Где найти лучшую открытую оценку и сравнение Qwen3
Что все ждут? Ответ простой — это непревзойденная сила инноваций и возможностей...
⭐ Особенности модели: глубокое мышление встречает молниеносную скорость
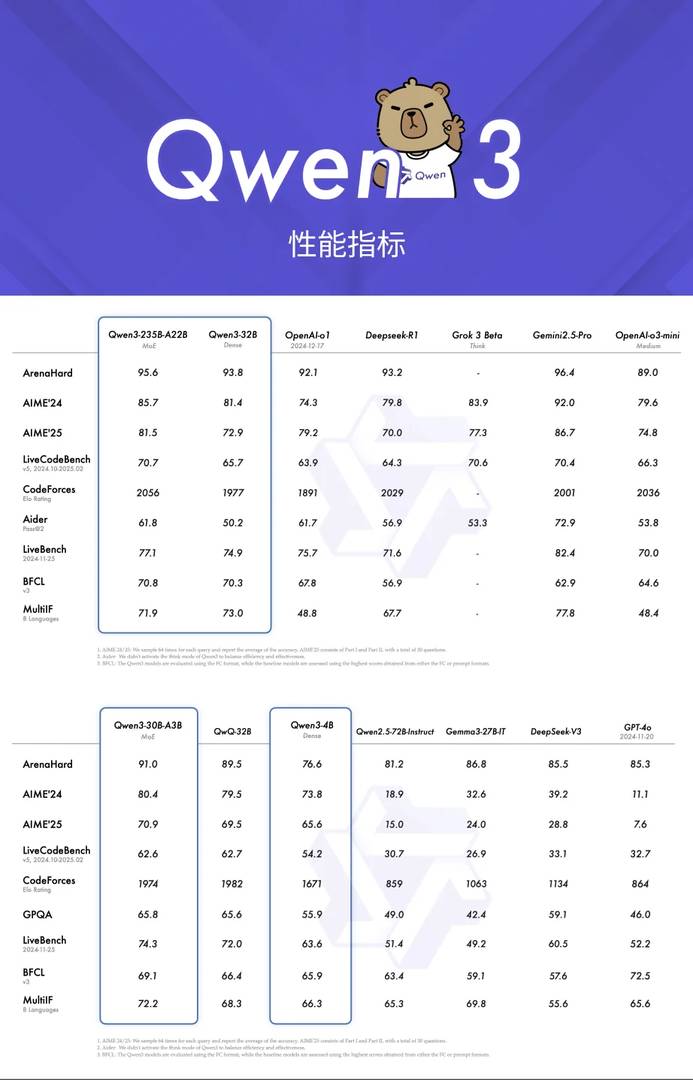
🚀 Представляем Qwen3 — самую мощную открытую модель в мире, превосходящую DeepSeek R1 во всех отношениях. Это историческая веха, как первый отечественный модель, достигший полного превосходства над R1, тогда как предыдущие модели могли только соответствовать его уровню производительности.
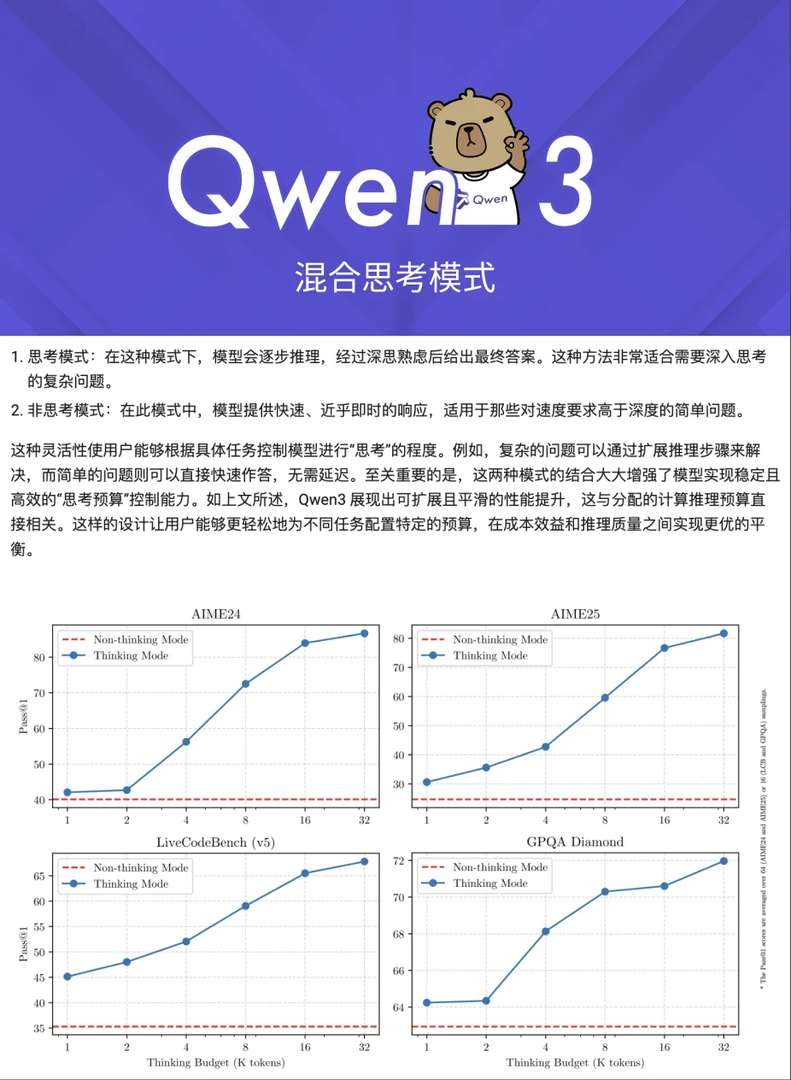
🤖 Qwen3 — первая в Китае гибридная модель вывода, разработанная для предоставления глубоких выводов для сложных вопросов 🧠 и мгновенных ответов на простые запросы ⚡. Плавное переключение между режимами повышает интеллектуальные способности, сохраняя при этом вычислительные ресурсы — настоящий прорыв.

💡 Требования к развертыванию были революционизированы. Флагманская модель теперь может быть развернута локально всего с 4 H20 GPU 💻, что снижает затраты более чем на 60% по сравнению с R1.
🧑💻 Возможности агента достигли новых высот, с родной поддержкой протокола MCP, значительно улучшая способности к программированию. Домашние инструменты агентов с нетерпением ожидают его выхода.
🌏 Поддерживает впечатляющие 119 языков и диалектов, включая региональные языки, такие как яванский и гаитянский креольский — Qwen3 гарантирует, что доступность ИИ не знает границ.
📊 Обучена на поразительном объеме 36 триллионов токенов, что в два раза больше, чем использовалось для Qwen2.5. Обучающие данные включают не только веб-контент, но и обширные материалы в формате PDF и синтезированные фрагменты кода.
💰 Развертывание стало еще более экономически эффективным. Флагманская модель требует всего 4 H20 GPU, что составляет одну треть от того, что требуется для R1, делая высокопроизводительное развертывание ИИ доступным широкой аудитории.
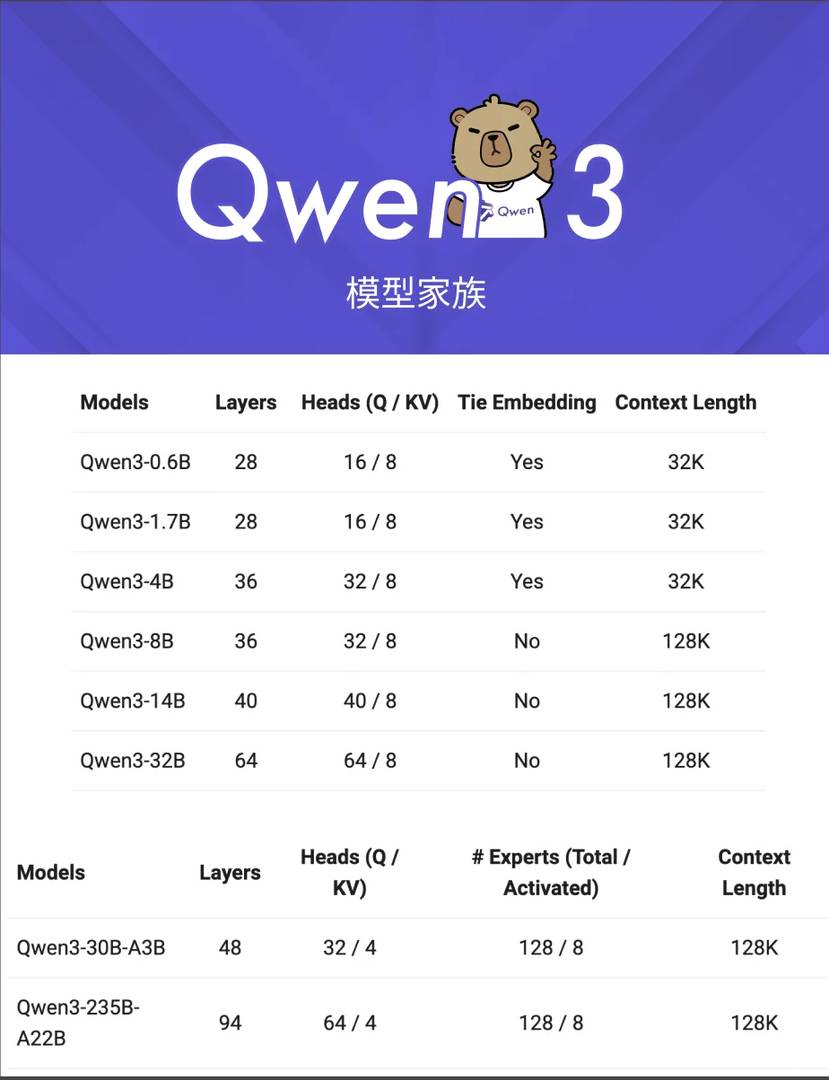
🏠 Познакомьтесь с семьей Qwen3:
Всего 8 моделей будут предоставлены в открытом доступе, включая 2 MoE-модели и 6 Dense-моделей. - 2 MoE Модели: - Флагманская Qwen3-235B-A22B, с активными параметрами всего 22B, снижая затраты на развертывание до одной трети от DeepSeek R1. - Мини-модель Qwen3-30B-A3B, с активными параметрами всего 3B, обеспечивающая производительность, сравнимую с Qwen2.
5-32B, идеальна для развертывания на потребительских GPU. - 6 Dense Моделей: 0.6B, 1.7B, 4B, 8B, 14B, 32B - Легковесная модель 0.6B даже может быть развернута на смартфонах, принося передовые технологии ИИ прямо в ваш карман.
Qwen3 здесь, полностью открытый исходный код и готов к исследованию. Ознакомьтесь с ним сегодня на официальном сайте или в GitHub.
Этот обзор Qwen3 выглядит впечатляюще! Особенно интересно узнать о его превосходстве над DeepSeek R1. Надеюсь, у модели будет много применений в реальных проектах. Буду следить за её развитием!
Очень впечатляет, что Qwen3 наконец-то превзошел DeepSeek R1 по всем параметрам! Жду не дождусь, когда смогу сам протестировать его в работе. Где можно найти самые объективные сравнения его производительности с другими моделями?
Спасибо за ваш энтузиазм! Самые объективные сравнения производительности Qwen3 с другими моделями (включая DeepSeek R1) вы найдете в разделе бенчмарков на официальном GitHub-репозитории Alibaba Cloud. Также рекомендую обратить внимание на свежие обзоры на Hugging Face — там часто публикуют детальные тесты с открытыми методиками оценивания. Лично я тоже восхищен прогрессом Qwen3 и считаю, что эти материалы помогут вам составить полное представление о возможностях модели