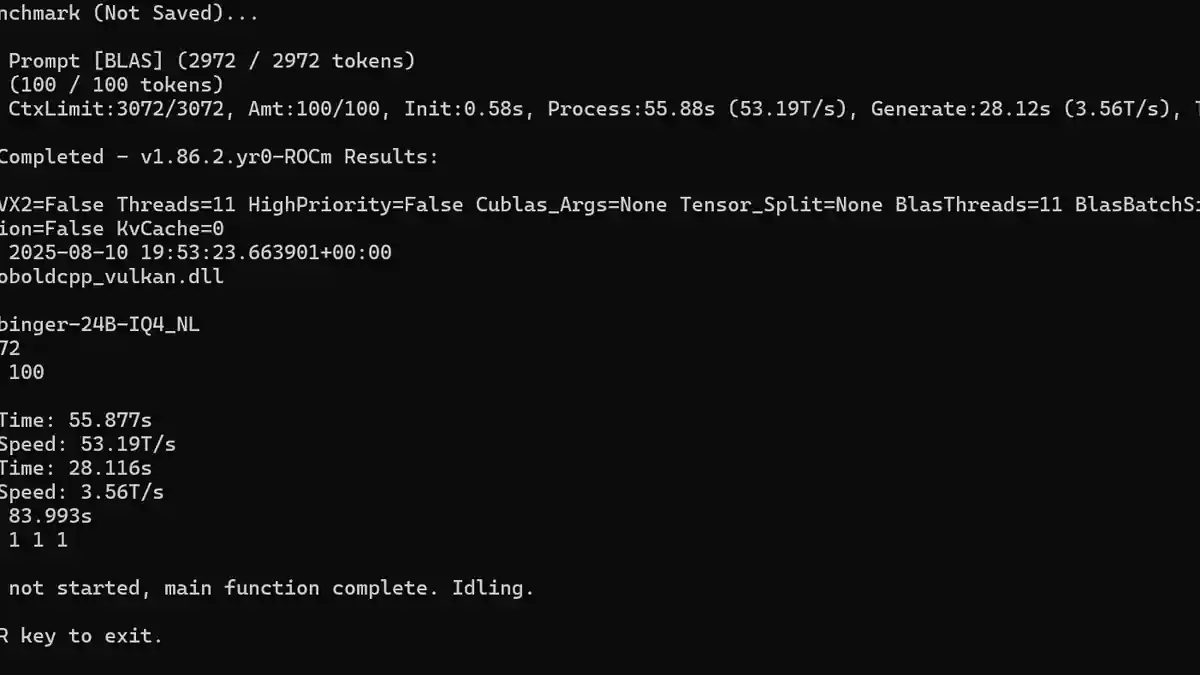
Когда запускаются локальные модели, какое время генерации ответов вы считаете разумным? Я интересуюсь, как другие воспринимают нормальные скорости обработки, особенно когда речь идет о фильтрации контекста, что я считаю самым утомительным. По крайней мере, при медленной генерации вы все еще можете оставаться вовлеченными, читая вывод по мере его появления.
Для меня скорость генерации, показанная на скриншоте, примерно такая медленная, какую я могу терпеть. Я экспериментировал с несколькими моделями, обычно более крупными, например, с 24-30 миллиардами параметров и некоторыми моделями, ориентированными на рассуждения, где токены в секунду (T/с) падали до около 14 T/с. Одна модель для рассуждений регулярно занимала около 10 минут на генерацию ответа. Хотя качество было в целом очень хорошим, я не достаточно терпелив для ролевых игр на такой скорости.
Моё оборудование включает RX 7900GRE, что уже ставит меня в невыгодное положение по сравнению с видеокартами Nvidia. Я обнаружил, что модели с 12-14 миллиардами параметров в диапазоне квантования q4 до q5 — это предел того, что может обрабатывать моя машина достаточно хорошо, если я не упускаю какие-то важные настройки или трюки оптимизации для повышения производительности.