Как максимизировать пропускную способность Qwen3 30B MOE на 4090 48G: Советы и insights производительности
Боже мой, этот модель кажется специально созданной для Агентов!
В 5 утра я взглянул на свой телефон и обнаружил, что Qwen3 только что был выпущен. Я подумал вернуться к сну, но возбуждение не давало мне уснуть. Я знал, что должен погрузиться в тестирование и проверить его весь день.
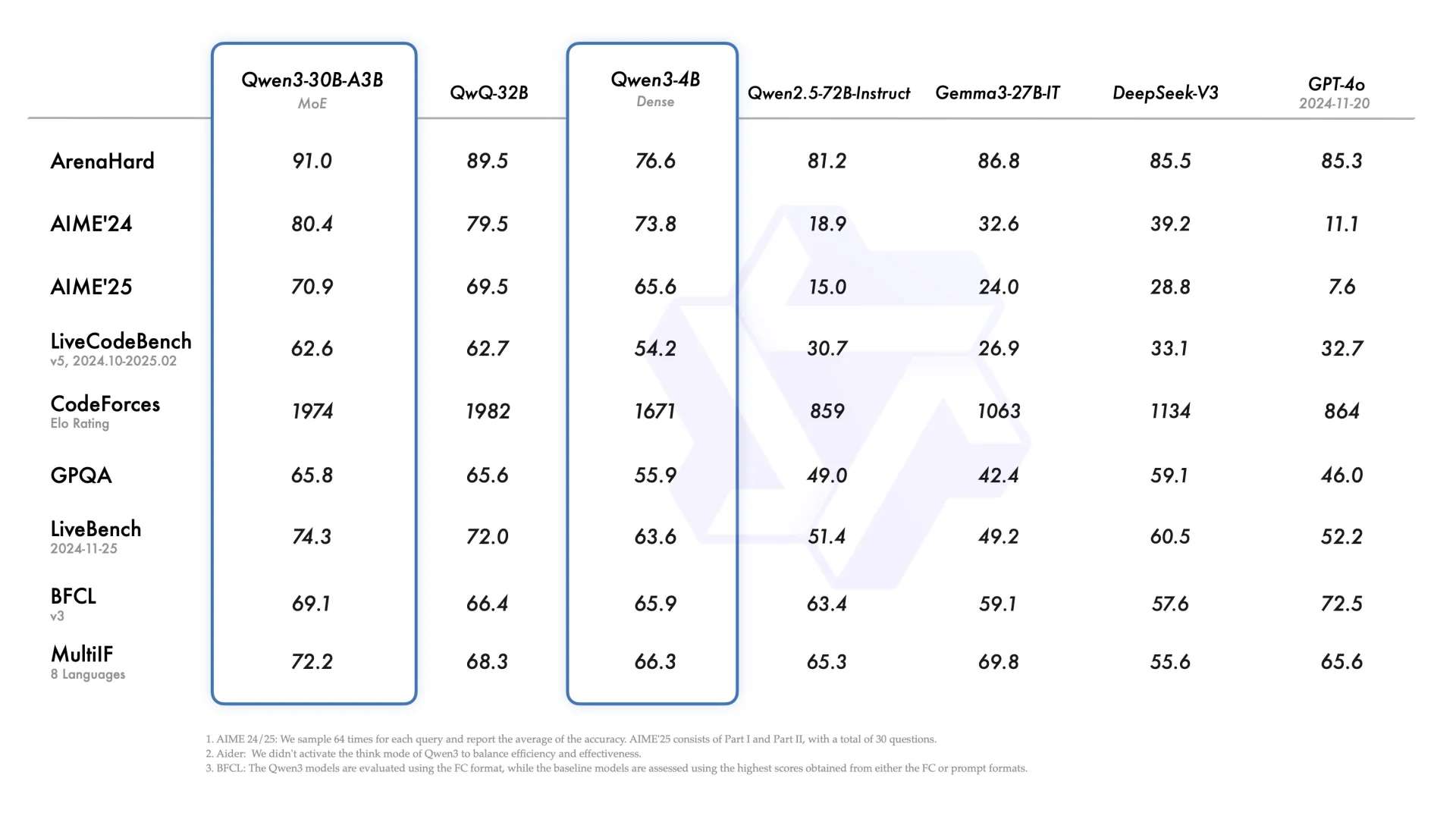
Когда я впервые увидел Qwen3-30B-A3B, первая мысль, которая пришла мне в голову: это может быть модель, созданная специально для Агентов.
На данный момент существуют две значительные проблемы при реализации Агентов: непрерывный вызов инструментов и управление потреблением токенов вместе со скоростью.
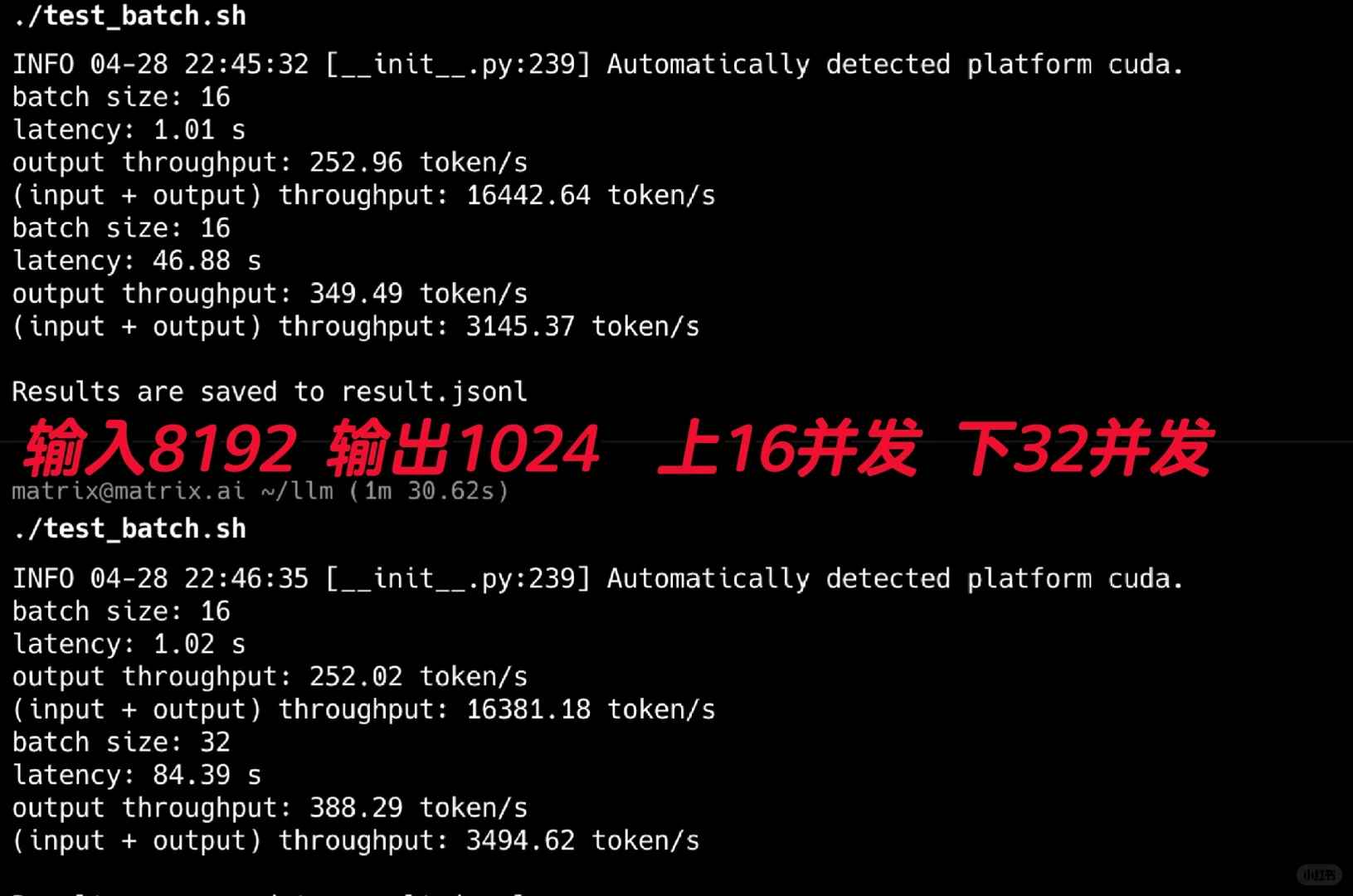
Я начал с тестирования пропускной способности, и результаты были потрясающими! Для этих тестов я использовал версию FP8. Как показано на рисунке 2, я провел 16 и 32 параллельных теста, имитируя типичные сценарии Агентов с длинными системными подсказками. Используя входной размер 8192 и установив выходной размер 1024, он достиг впечатляющей производительности вывода в 388t/s.
Имейте в виду, что эта производительность была достигнута всего на одном GPU 4090. Похоже, что даже требования внутренних Агентов небольшой компании могли бы быть удовлетворены всего одним или двумя 4090, используя эту модель.
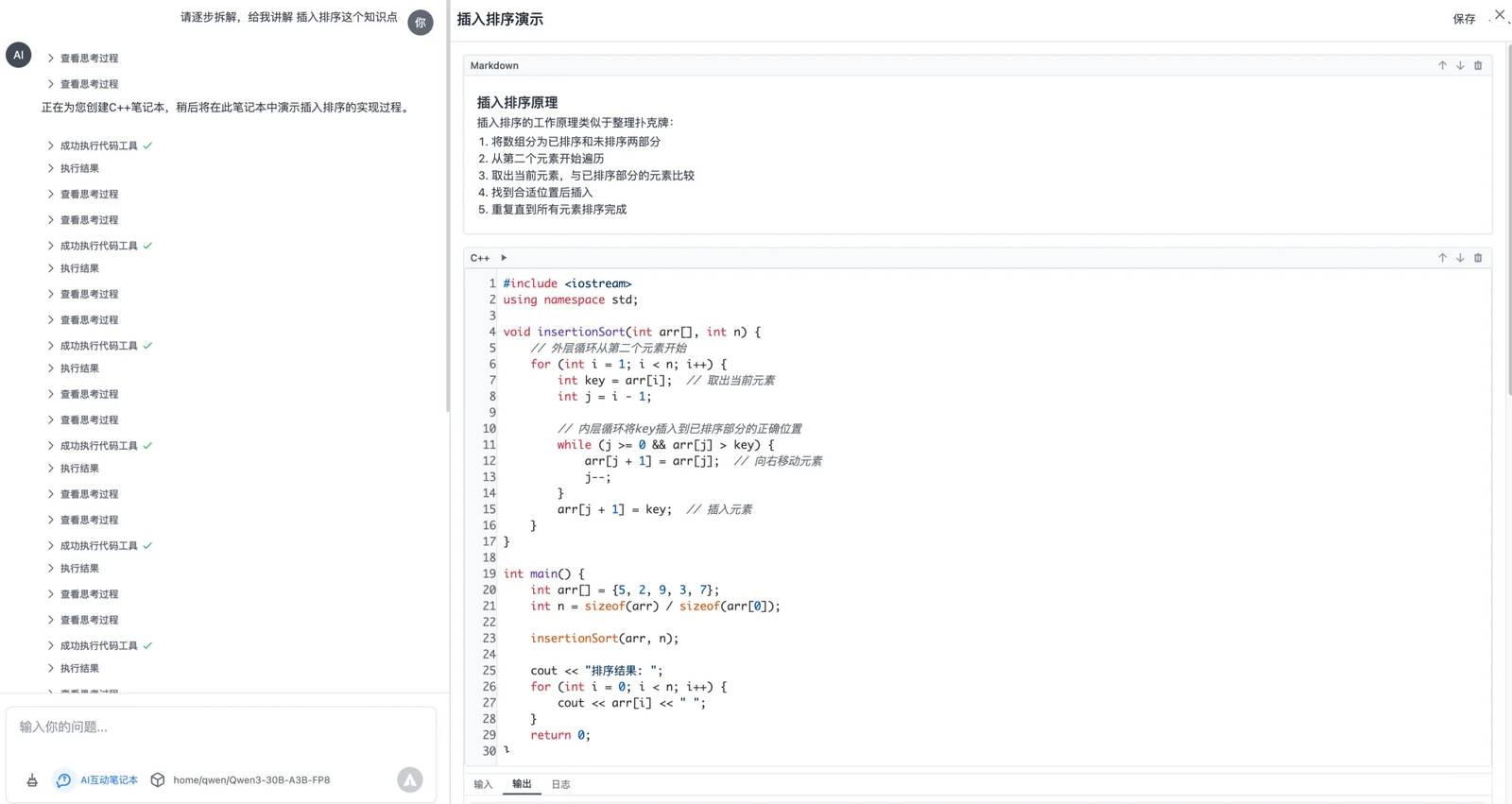
Далее я протестировал его в своей собственной специфической сценарии. Мой помощник по решению задач на C++ почти готов к тестированию. Он использует протокол MCP для создания интерактивной тетради. Вы можете задавать вопросы на C++, и он генерирует шаг за шагом исполняемую тетрадь кода, что значительно повышает эффективность обучения, особенно для детей.
Эта конкретная сцена включает несколько раундов вызова инструментов, где ИИ непрерывно оперирует и выполняет инструменты, анализируя результаты. Результаты тестов были просто идеальными!
В каждом раунде модель внимательно оценивает текущий статус задачи и определяет следующие шаги. Очевидно, что эта модель была обучена специально для многораундовых задач, и я с нетерпением ждал чего-то подобного уже давно.
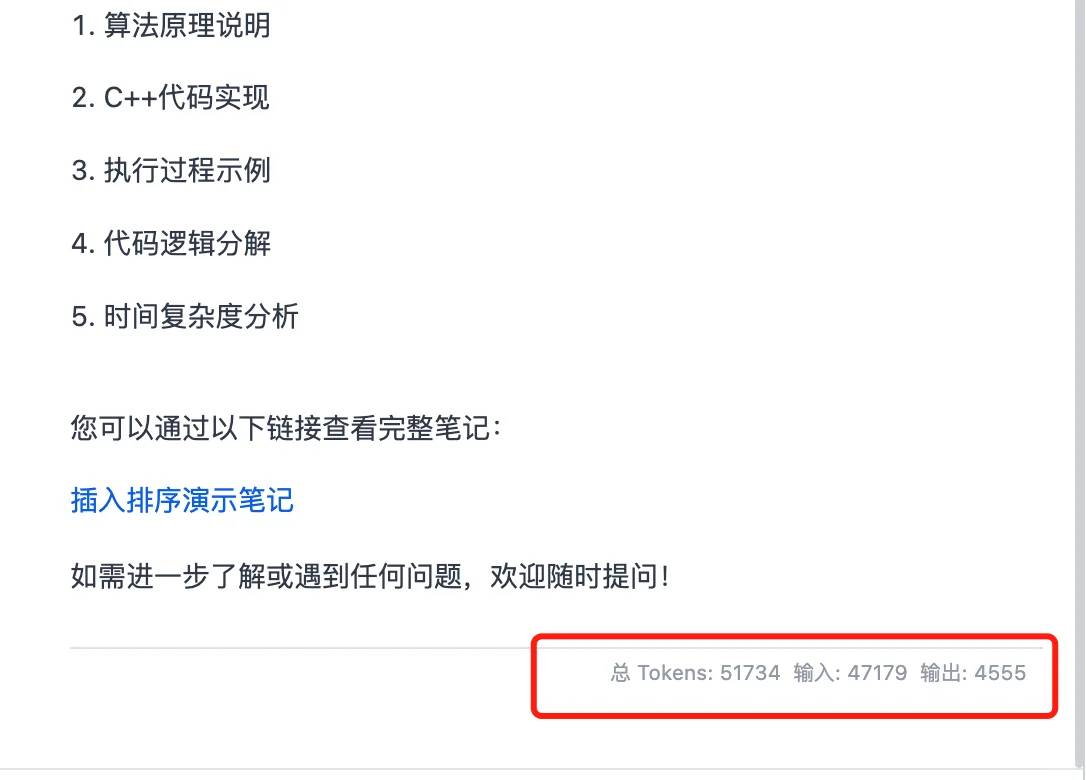
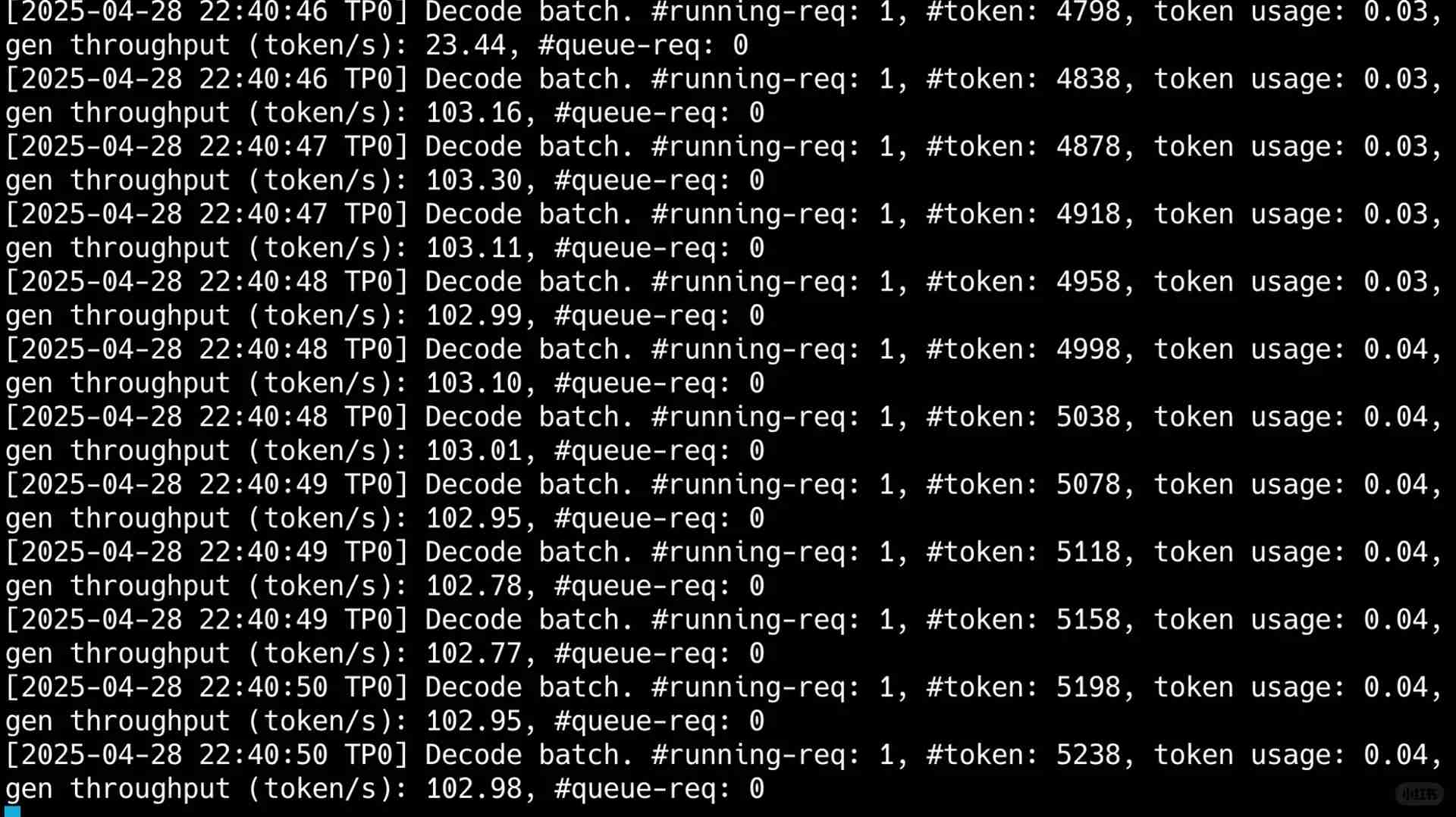
Что действительно меня поразило, так это пропускная способность одного пользователя, которая превысила 100t в секунду. Как вы можете видеть на моем последнем изображении, несмотря на потребление 50,000 токенов в сценарии с несколькими раундами использования инструментов, скорость вывода была молниеносной, завершив весь процесс всего за 40 секунд.
Может ли будущее выглядеть так: использование компактной активации MOE для решения как проблем скорости, так и стоимости, обеспечивая стабильную производительность при решении самых сложных задач в Агентах?
Ожидание было полностью оправдано. В ближайшие дни я продолжу углубленное тестирование этих моделей на основе сценария моего ученика по C++. Кроме того, относительно модели 200B+, я считаю, что возможно запустить ее на одном устройстве с некоторой доработкой с помощью Ktransformer. Есть ли кто-нибудь заинтересованный? Если да, я с удовольствием проведу дополнительное тестирование.
Это действительно впечатляет! Я заметил, что оптимизация использования VRAM имеет огромное значение для производительности. Возможно, стоит также рассмотреть способы уменьшения размера токенов на входе. Удачи с дальнейшими экспериментами!
Очень интересная статья! Я как раз разбираюсь с оптимизацией больших моделей на ограниченном железе, и ваши советы по ускорению Qwen3 на 4090 выглядят крайне полезно. Особенно зацепил момент про настройку для Agents — сразу видно, что автор действительно “в теме” и тестировал всё на практике. Обязательно попробую эти фишки в своём проекте!