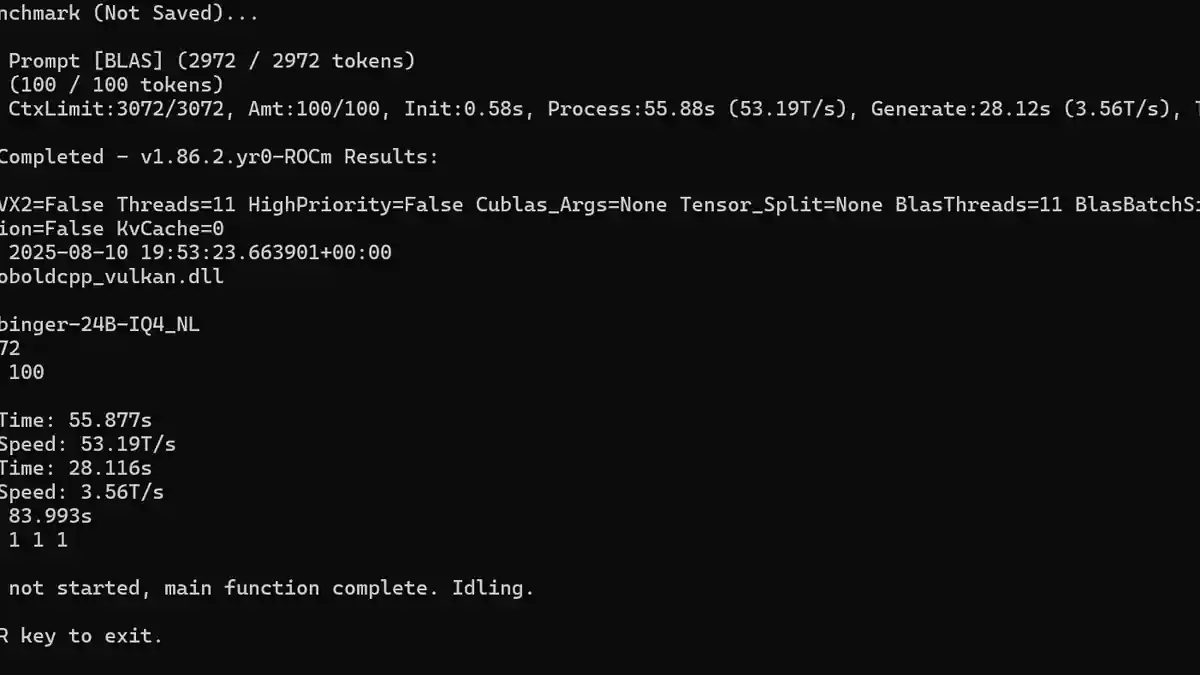
Ao executar modelos locais, o que você considera um tempo de geração razoável para respostas? Estou curioso sobre o que outros consideram velocidades de processamento normais, especialmente quando se trata de filtrar o contexto, que acho ser a parte mais trabalhosa. Pelo menos com uma geração lenta, você ainda pode se manter envolvido lendo a saída à medida que ela aparece gradualmente.
Para mim, a velocidade de geração mostrada na captura de tela é tão lenta quanto consigo tolerar. Experimentei vários modelos, geralmente maiores, como de 24-30B de parâmetros e alguns modelos focados em raciocínio, onde os tokens por segundo (T/s) caíam para cerca de 14T/s. Um modelo de raciocínio levava regularmente cerca de 10 minutos para gerar uma resposta. Embora a qualidade fosse geralmente muito boa, não tenho paciência suficiente para jogos de papéis a esse ritmo.
Meu equipamento inclui um RX 7900GRE, o que já me coloca em desvantagem em comparação com placas Nvidia. Descobri que modelos de 12B a 14B de parâmetros na faixa de quantização q4 a q5 são o limite do que minha máquina consegue lidar razoavelmente bem, a menos que eu esteja ignorando alguma configuração ou truque de otimização crucial para melhorar o desempenho.