Como Maximizar o Throughput do Qwen3 30B MOE em uma 4090 48G: Dicas e Insights de Desempenho
Meu Deus, este modelo parece ter sido criado especificamente para Agentes!
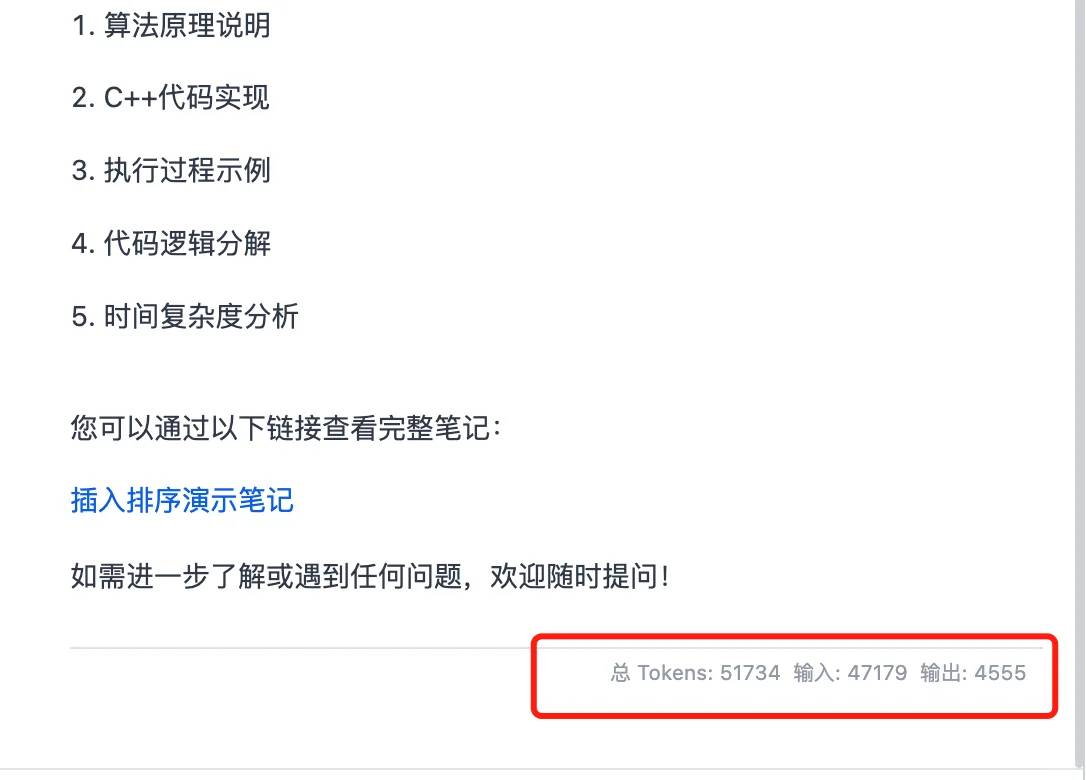
Às 5 da manhã, eu olhei para o meu celular e descobri que o Qwen3 havia acabado de ser lançado. Pensei em voltar a dormir, mas a empolgação me manteve acordado. Sabia que tinha que mergulhar e testá-lo o dia todo.
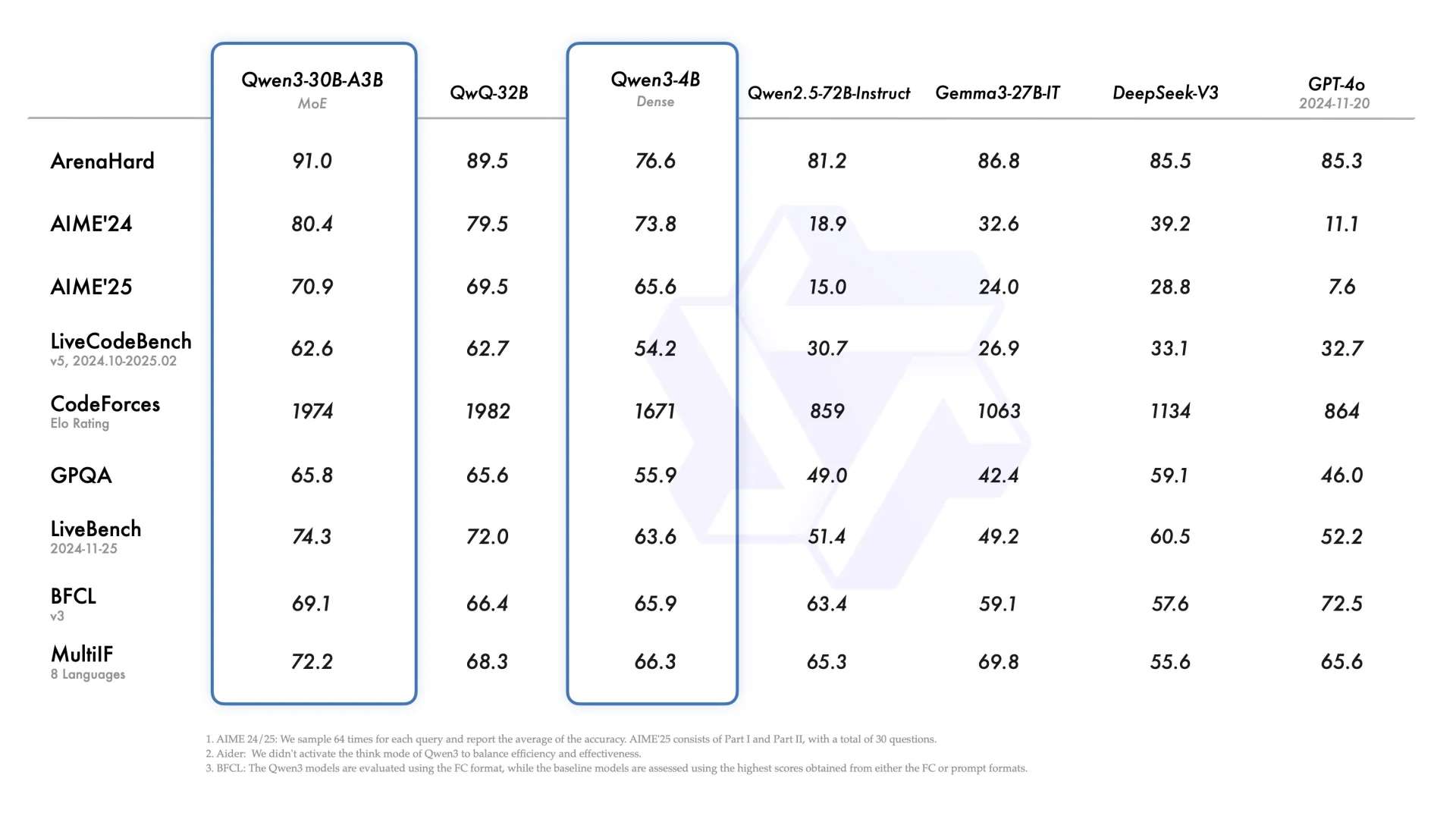
Quando vi pela primeira vez o Qwen3-30B-A3B, uma ideia me veio à mente imediatamente: este poderia muito bem ser um modelo criado pensando nos Agentes.
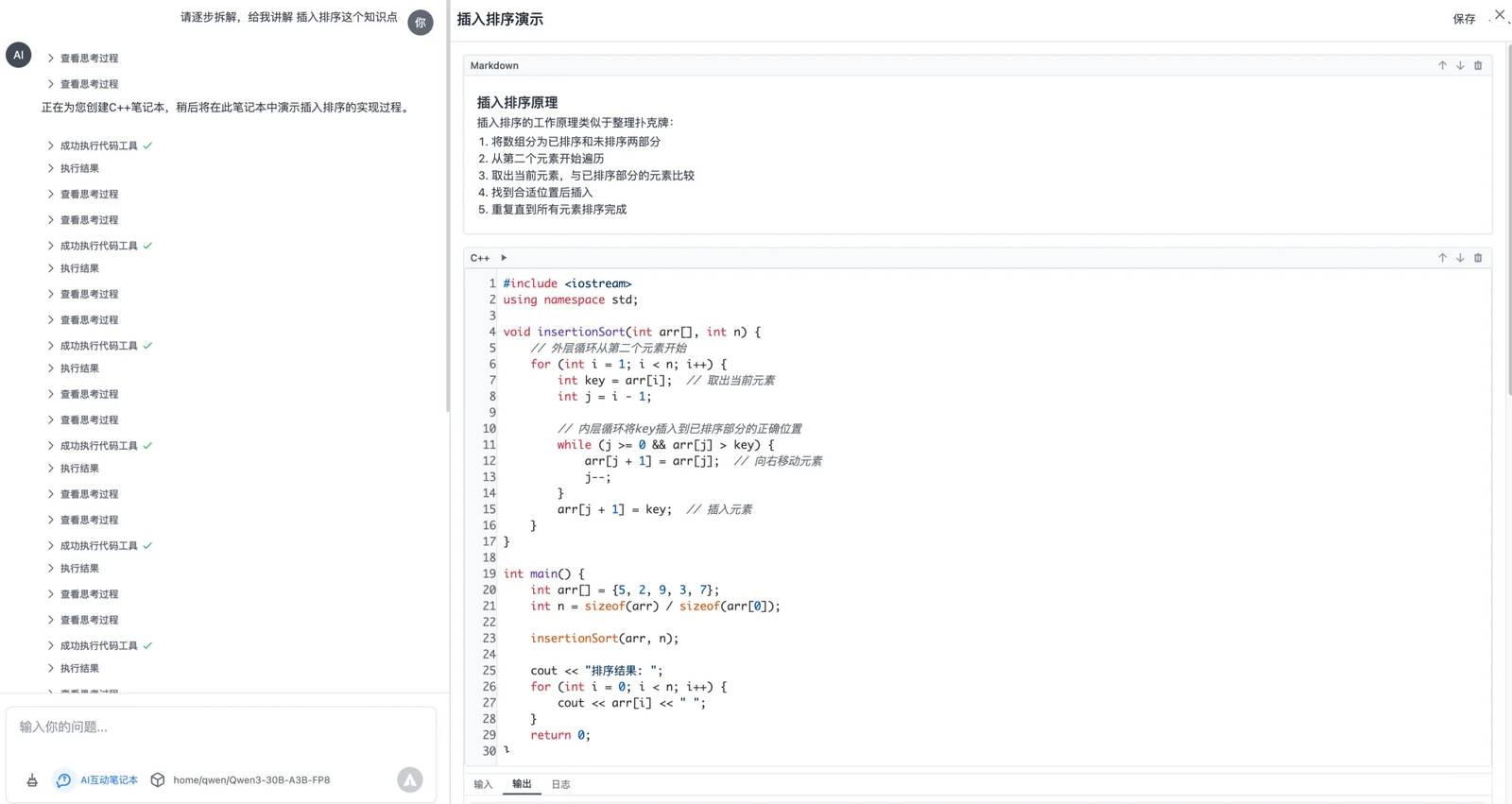
No momento, há dois desafios significativos ao implementar Agentes: invocação contínua de ferramentas e gerenciamento do consumo de tokens junto com a velocidade.
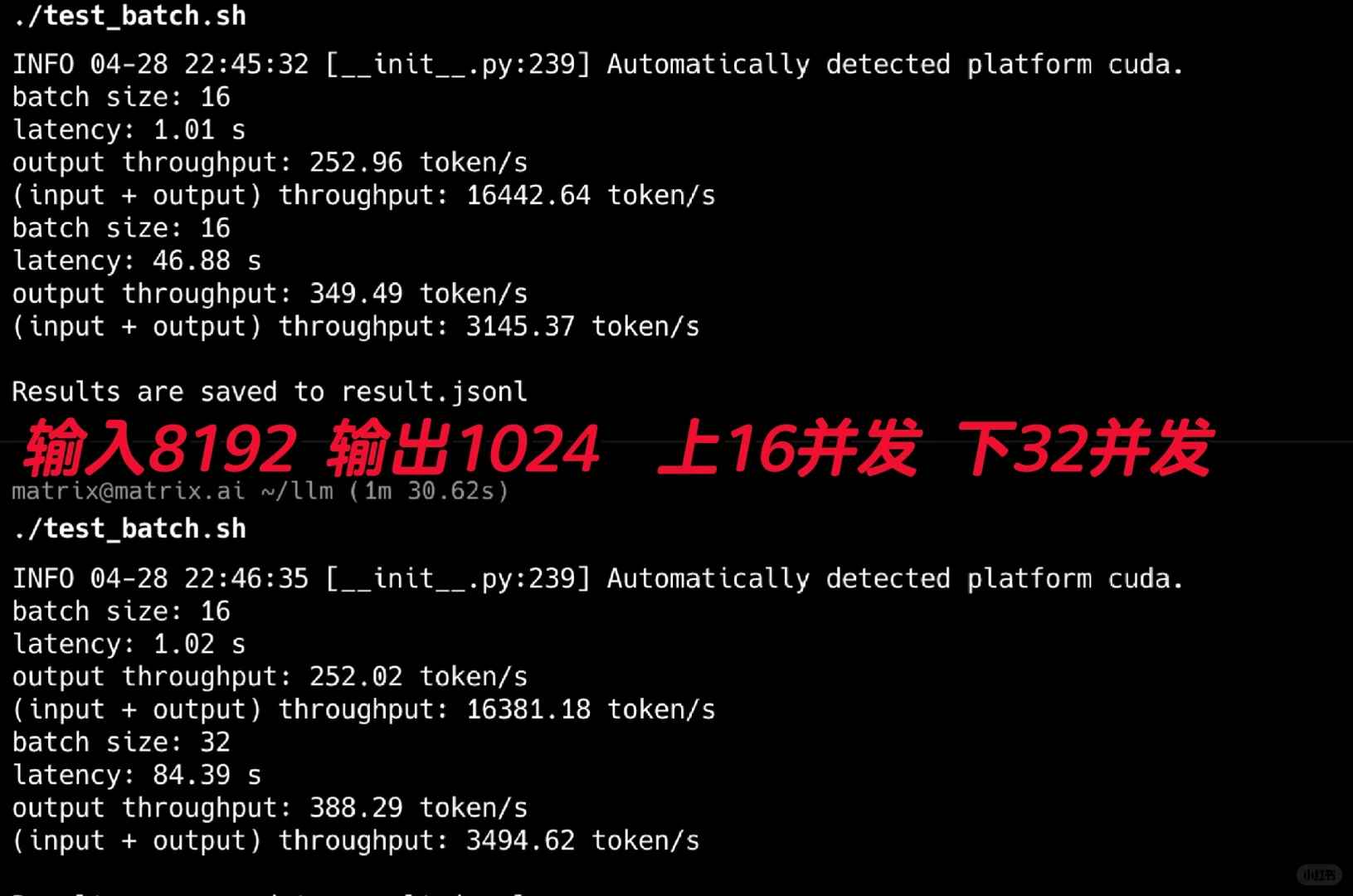
Eu comecei testando seu throughput, e os resultados foram impressionantes! Usei a versão FP8 para esses testes. Como mostrado na Figura 2, realizei testes com 16 e 32 concorrências simultâneas, simulando cenários típicos de Agentes com prompts de sistema extensos. Usando uma entrada de 8192 e definindo a saída como 1024, ele alcançou uma impressionante taxa de saída de 388t/s.
Lembre-se, esse desempenho foi obtido em apenas uma GPU 4090. Parece que até as necessidades internas de Agentes de uma pequena empresa poderiam ser atendidas com apenas uma ou duas GPUs 4090 usando este modelo.
Em seguida, testei-o no meu próprio cenário específico. Meu assistente de resolução de problemas em C++ está quase pronto para testes. Ele aproveita o protocolo MCP para criar um caderno interativo. Você pode fazer perguntas em C++ para ele, e ele gera um caderno de código executável passo a passo, o que aumenta muito a eficiência de aprendizado, especialmente para crianças.
Este cenário específico envolve múltiplas rodadas de invocação de ferramentas, onde a IA opera e executa ferramentas continuamente enquanto analisa os resultados. Os resultados dos testes foram perfeitos!
Em cada rodada, o modelo avalia cuidadosamente o status atual da tarefa e determina os próximos passos. Claramente, este modelo foi treinado especificamente para tarefas multirrounds, e eu estive esperando algo assim por bastante tempo.
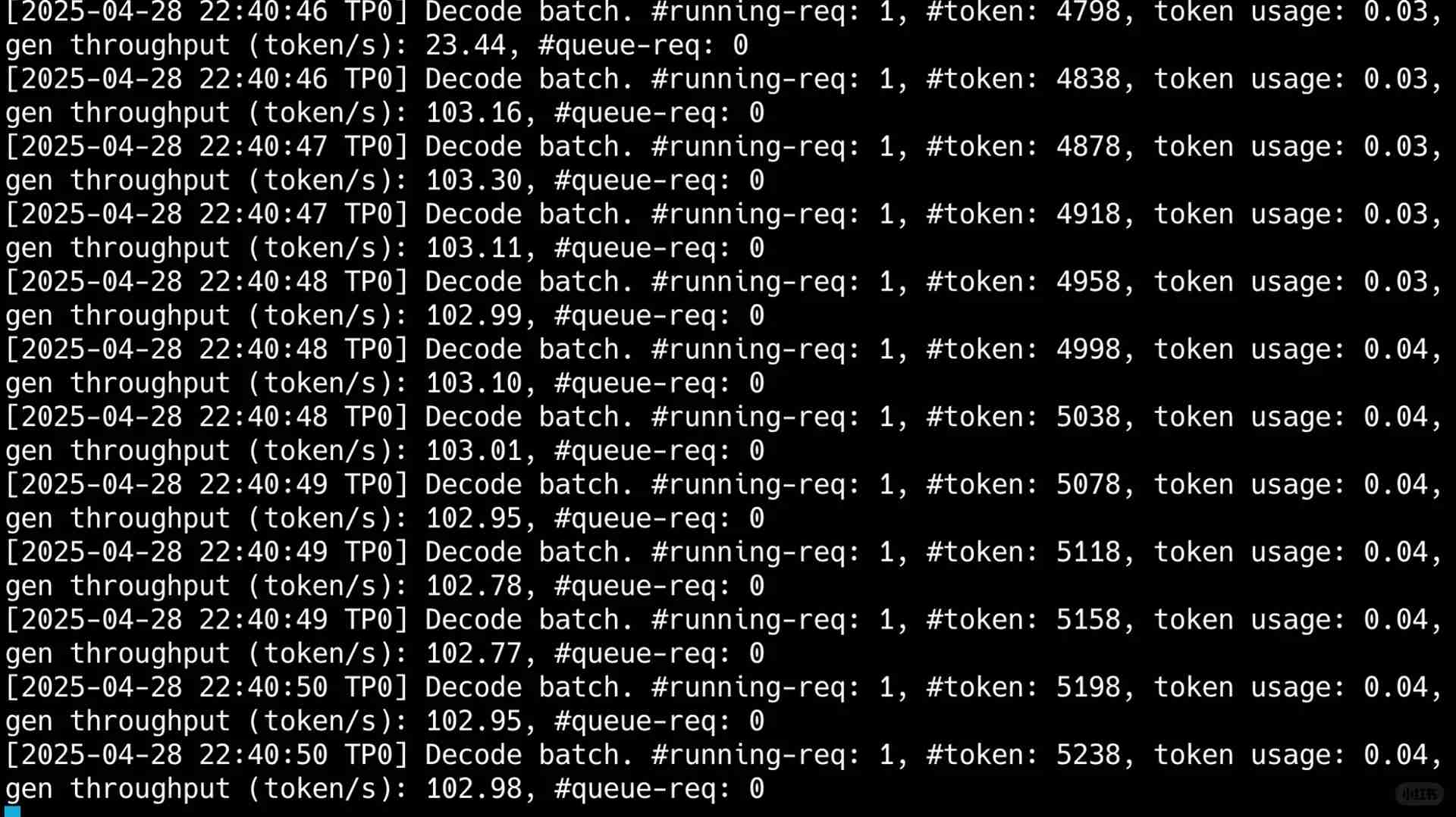
O que realmente me surpreendeu, no entanto, foi o throughput de um único usuário, que superou 100t por segundo. Como você pode ver na minha última imagem, apesar de consumir 50.000 tokens em um cenário envolvendo múltiplas rodadas de uso de ferramentas, a velocidade de saída foi incrivelmente rápida, completando todo o processo em apenas 40 segundos.
Poderia o futuro ser assim: usar um MOE de ativação compacto para abordar tanto a velocidade quanto as preocupações de custo, entregando um desempenho sólido ao enfrentar os problemas mais complexos em Agentes?
A espera valeu a pena. Nos próximos dias, continuarei realizando testes aprofundados nesses modelos com base no cenário de meu Agente de aprendizado em C++. Além disso, em relação ao modelo de 200B+, acredito que seja factível executá-lo em uma única máquina com algumas ajustes usando Ktransformer. Alguém está interessado? Se sim, ficaria feliz em realizar mais testes.
Que artigo incrível! Também fiquei animadíssimo com o lançamento do Qwen3 e já queria testar logo nas primeiras horas. Suas dicas sobre otimização na 4090 vão me ajudar muito nos meus experimentos com agents.