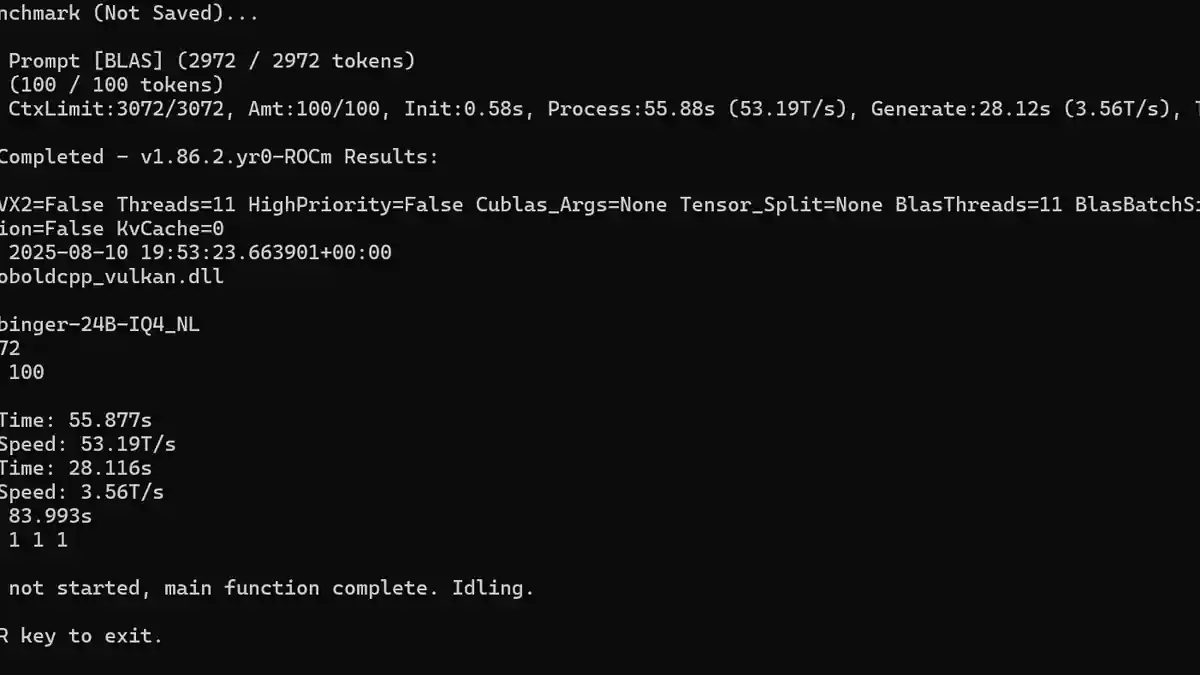
When running local models, what do you consider a reasonable generation time for responses? I’m curious about what others view as normal processing speeds, particularly when it comes to sifting through context, which I find to be the most tedious part. At least with slow generation, you can still stay engaged by reading the output as it gradually appears.
For me, the generation speed shown in the screenshot is about as slow as I can tolerate. I’ve experimented with several models, generally larger ones like 24-30B parameters and some reasoning-focused models, where the tokens per second (T/s) would drop to around 14T/s. One reasoning model regularly took about 10 minutes to generate a response. Although the quality was generally very good, I’m not patient enough for roleplaying at that pace.
My setup includes an RX 7900GRE, which already puts me at a disadvantage compared to Nvidia cards. I’ve found that 12B to 14B parameter models in the q4 to q5 quantization range are the limit of what my machine can handle reasonably well, unless I’m overlooking some crucial settings or optimization tricks to improve performance.