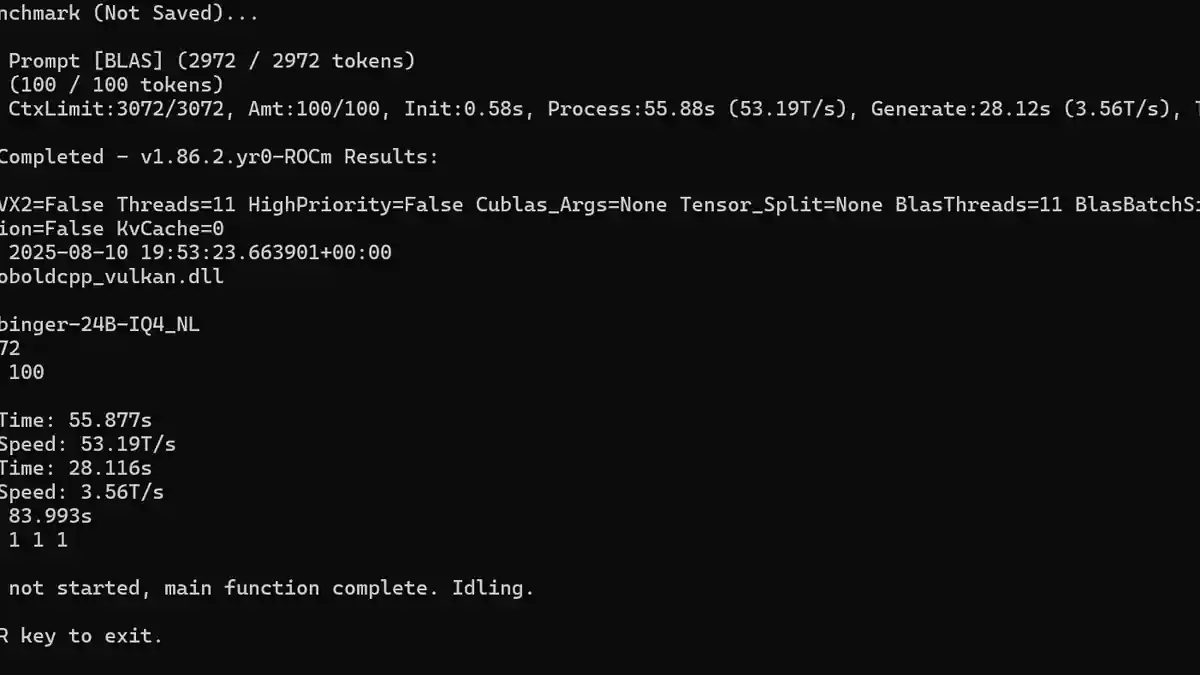
ローカルモデルを実行する際、応答の生成にどれくらいの時間を合理的だと考えていますか?他の人が通常の処理速度としてどのように見ているのか気になっています。特に文脈を吟味する作業については、最も面倒だと感じているためです。少なくとも生成が遅い場合でも、出力が次第に表示されるのを読むことで、依然として関与し続けることができます。
私にとって、スクリーンショットに表示されている生成速度は私が耐えられる限界に近いです。いくつかのモデルを試してみました。一般的にパラメータ数が多いもので、24〜30Bと、推論に特化したモデルがあり、トークン毎秒(T/s)は約14T/sまで下がりました。一つの推論モデルでは、応答を生成するのに約10分かかりました。品質は基本的に非常に良かったですが、そのペースでロールプレイをするには私の忍耐力が足りません。
私の環境にはRX 7900GREが搭載されており、Nvidiaカードと比べてすでに不利な立場にあります。私は12B〜14Bのパラメータを持つモデルで、q4からq5の量子化範囲において、私のマシンが比較的よく動作できる限界であることを発見しました。ただし、パフォーマンスを向上させるために何か重要な設定や最適化テクニックを見落としている可能性もあります。