How to Maximize Qwen3 30B MOE Throughput on a 4090 48G: Tips & Performance Insights
Oh my goodness, this model feels like it was crafted specifically for Agents!
At 5 a.m., I glanced at my phone and discovered that Qwen3 had just been released. I thought about going back to sleep, but the excitement kept me awake. I knew I had to dive in and test it all day long.
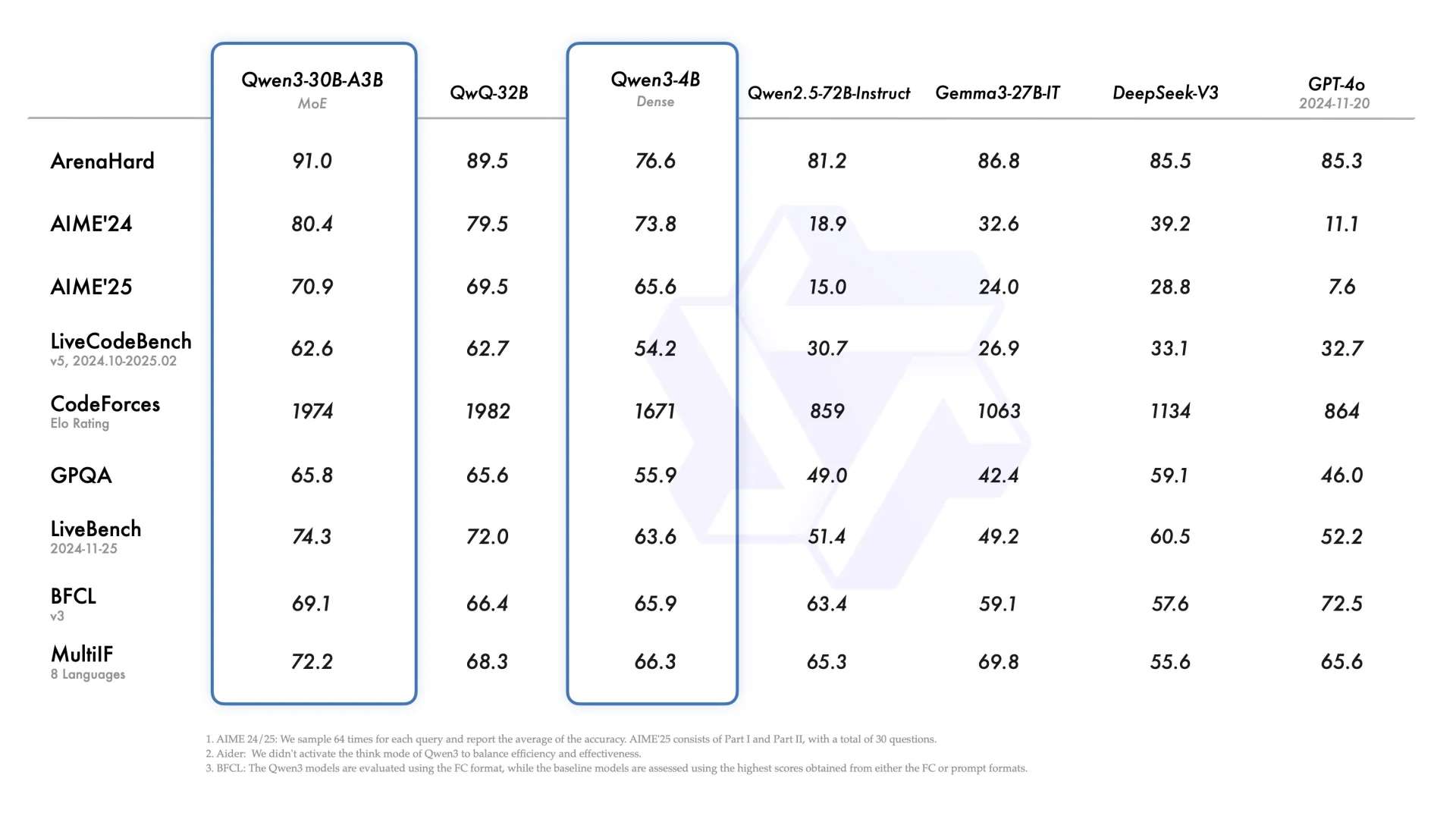
When I first laid eyes on Qwen3-30B-A3B, one thought immediately struck me: this could very well be a model designed with Agents in mind.
Currently, there are two significant challenges when it comes to implementing Agents: continuous tool invocation and managing token consumption alongside speed.
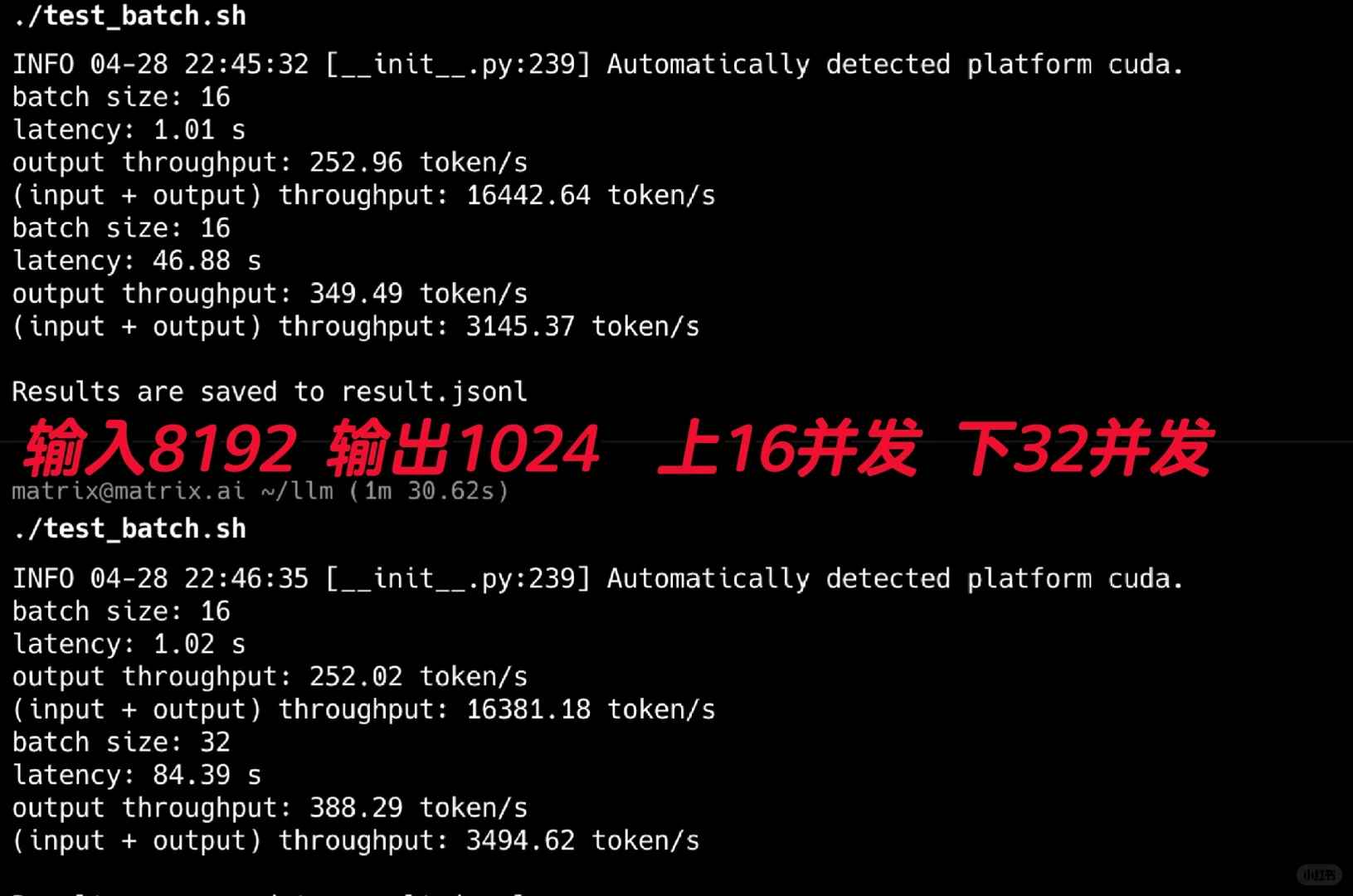
I started by testing its throughput, and the results were jaw-dropping! I used the FP8 version for these tests. As shown in Figure 2, I conducted 16 and 32 concurrent tests, simulating typical Agent scenarios with lengthy system prompts. Using an input of 8192 and setting the output to 1024, it achieved an impressive output throughput of 388t/s.
Keep in mind, this performance was achieved on just a single 4090 GPU. It seems that even a small company’s internal Agent requirements could be met with just one or two 4090s using this model.
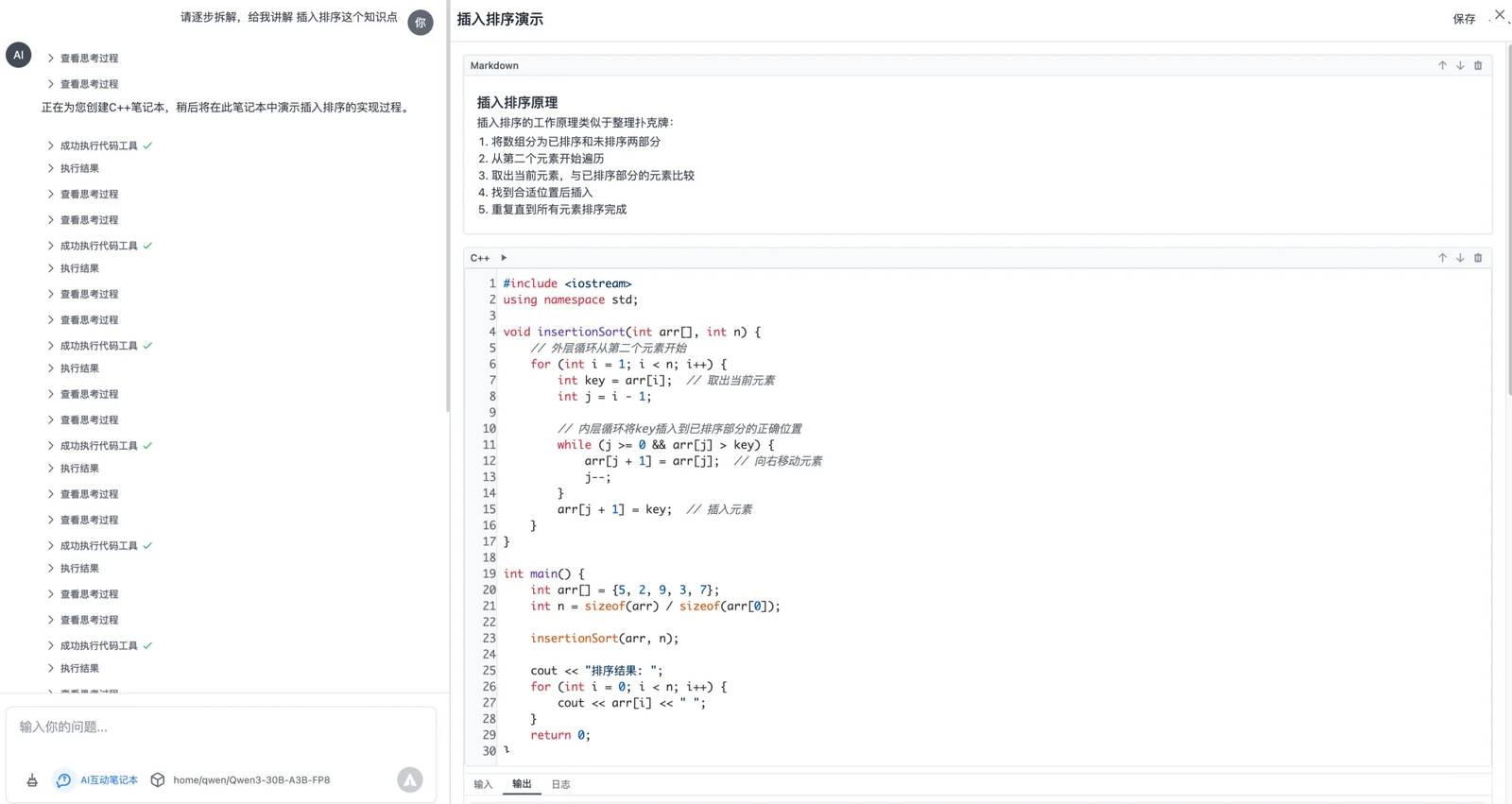
Next, I tested it under my own specific scenario. My C++ problem-solving assistant is nearly ready for testing. It leverages the MCP protocol to create an interactive notebook. You can pose C++ questions to it, and it generates a step-by-step executable code notebook, which greatly enhances learning efficiency, especially for children.
This particular scenario involves multiple rounds of tool invocation, where the AI continuously operates and executes tools while analyzing the results. The test results were nothing short of perfect!
In each round, the model carefully evaluates the current task status and determines the next steps. Clearly, this model has been trained specifically for multi-round tasks, and I’ve been eagerly waiting for something like this for quite some time.
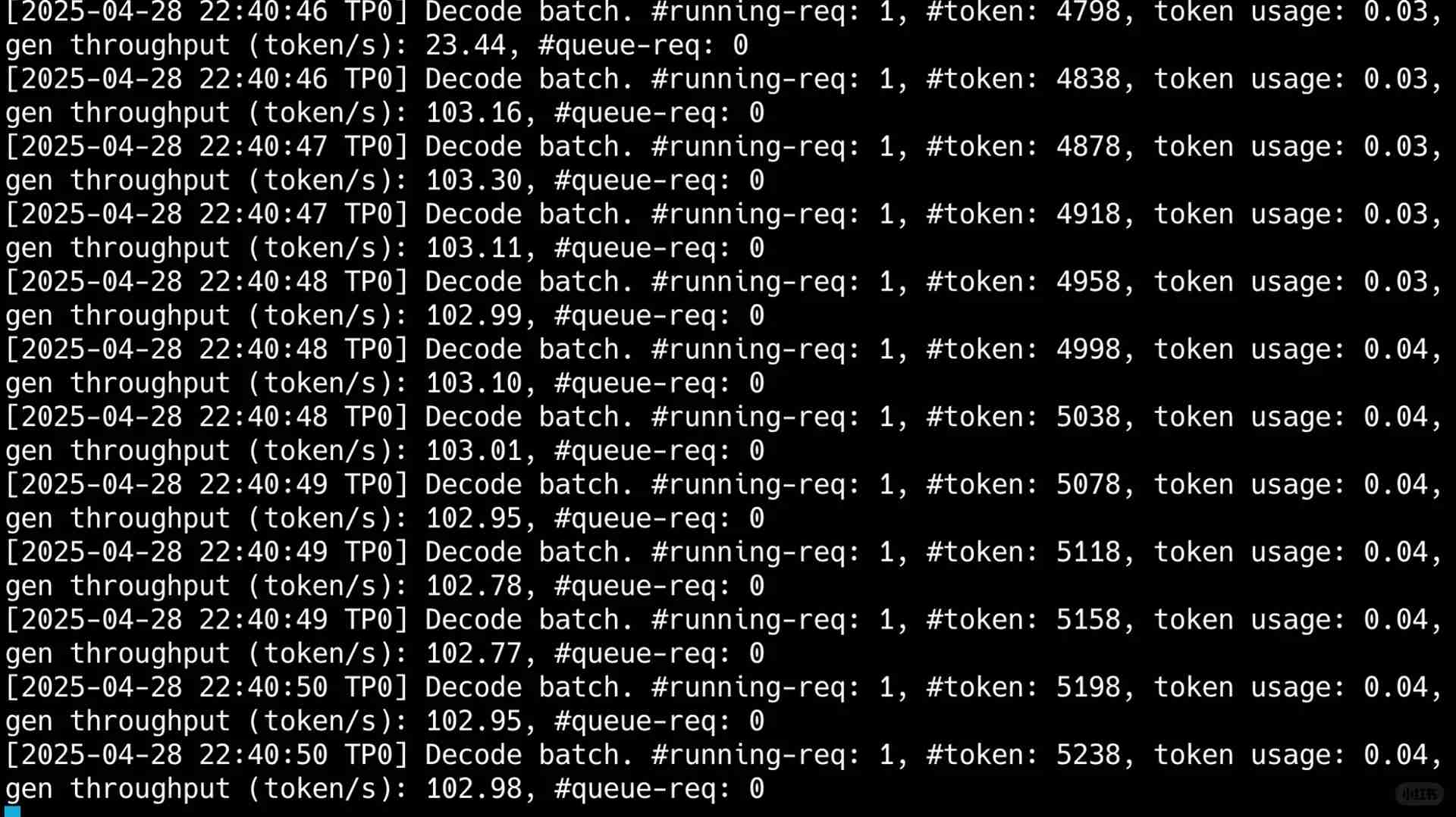
What truly astonished me, however, was the single-user throughput, which exceeded 100t per second. As you can see in my final image, despite consuming 50,000 tokens in a scenario involving multiple rounds of tool usage, the output speed was lightning-fast, completing the entire process in just 40 seconds.
Could the future look like this: using a compact activation MOE to address both speed and cost concerns, delivering solid performance while tackling the most complex problems in Agents?
The wait was absolutely worth it. In the coming days, I’ll continue conducting in-depth tests on these models based on my C++ learning Agent scenario. Moreover, regarding that 200B+ model, I believe it might be feasible to run it on a single machine with some fine-tuning using Ktransformer. Is anyone interested? If so, I’d be happy to conduct further testing.
I’m still wrapping my head around how much optimization went into getting the most out of that GPU with Qwen3. It’s wild to think about how much performance you can squeeze out just by tweaking some settings. The part about memory allocation really resonated with me since I ran into similar issues last week. Definitely bookmarked this for future reference when I need to push these models harder.
I tried the tips in this article and saw a noticeable improvement in throughput—adjusting batch sizes really made a difference. It’s impressive how much performance can vary based on these small tweaks. I wonder if there are any other optimizations they’ll add in future updates. Exciting stuff!
I totally get the early-morning excitement! The tips in this article are super helpful, especially about optimizing GPU memory usage. It’s impressive how much throughput you can squeeze out of Qwen3 with the right tweaks. I’m definitely going to try these strategies myself.
I was blown away by how much throughput you can squeeze out of Qwen3 on a 4090. The tips about memory allocation really made a difference for my setup. It’s impressive how these models keep getting better and more efficient. I wonder what the next big update will bring.
Thank you for your kind words! I’m glad the tips were helpful. You’re right, the progress in model efficiency is remarkable. As for the future, I’m excited to see how quantization and sparsity could push performance even further. Keep exploring and sharing your discoveries!
I tried the tips from this article and saw a noticeable improvement in throughput. It’s impressive how much difference small tweaks can make, especially with such a large model on limited GPU memory. The part about adjusting batch sizes really stood out to me—will definitely experiment more with that.
I really appreciate the detailed tips on optimizing Qwen3’s performance—it’s clear you put a lot of effort into testing different configurations. The part about adjusting the batch size especially resonated with me since I noticed similar improvements when tweaking that setting myself. It’s fascinating how much difference minor changes can make!
Wow, your enthusiasm is contagious! I’ve been struggling with Qwen3’s throughput on my 4090 setup too, so these tips came at the perfect time. That 5am excitement totally sounds like something I’d do when new models drop!
Wow, staying up at 5am for Qwen3 sounds exactly like something I’d do too! The performance insights here are super helpful – I’ve been struggling to optimize my 4090 setup, so these tips are coming at the perfect time. That MOE architecture really does feel game-changing for agent workflows.
Glad to hear these tips resonated with your late-night AI tinkering—sounds like we share the same dedication! The MOE architecture truly is a game-changer, especially for agent workflows where every bit of throughput matters. Let me know if you run into any specific challenges with your 4090 setup—I’d love to help troubleshoot!
Wow, your excitement about Qwen3 is contagious! I’ve been struggling with throughput on my 4090 setup too, so these tips came at the perfect time. That 5am discovery moment sounds exactly like something I’d do when a new model drops!
Glad you found the tips helpful—those late-night eureka moments are what make tinkering with models so rewarding! The 4090 can be tricky with throughput, but Qwen3’s MOE architecture really shines once optimized. Let me know if you hit any snags implementing the suggestions!
Wow, your excitement about Qwen3 is contagious! I’ve been struggling with throughput on my 4090 setup too – your tips look super practical. Can’t wait to try that early morning testing energy myself!
Thanks for your kind words – I’m thrilled you found the tips helpful! Early morning testing really does make a difference when chasing those throughput numbers. Let me know how it goes with your setup, and don’t hesitate to reach out if you hit any snags!
Wow, staying up at 5am to test Qwen3 sounds exactly like something I’d do! Those throughput tips for the 4090 are super helpful—been struggling to optimize my setup. Can’t wait to try these tweaks tonight!
Glad to hear these tips resonate with your late-night tinkering spirit! The 4090’s 48G really shines with Qwen3 when you dial in those optimizations – let us know how your tests go. (Personally love seeing how much performance we can squeeze out of consumer GPUs these days!)
Wow, your excitement about Qwen3 is contagious! I’ve been struggling with throughput on my 4090 setup too, so these tips came at the perfect time. That 5am model-checking dedication is totally something I’d do as well!
Wow, staying up at 5 a.m. just to test Qwen3—that’s some serious dedication! Your throughput tips for the 4090 are super practical, especially the part about optimizing for agent-based workflows. Definitely trying this setup over the weekend.
Thanks so much for your kind words—I’m really glad you found the throughput tips practical! It’s awesome to hear you’re planning to try the setup this weekend; I think you’ll be impressed with how well it handles agent-based workflows. Let me know how it goes!
Wow, staying up at 5 a.m. just to test Qwen3—that’s some serious dedication! Your throughput tips for the 4090 are super practical, especially the part about optimizing for agent-based workflows. Definitely trying this setup over the weekend.
Wow, staying up at 5 a.m. just to test Qwen3—that’s some serious dedication! The tips for maximizing throughput on a 4090 are super practical, especially for running agentic workflows. Definitely going to try these optimizations myself.
Thanks so much for your kind words—I’m really glad you found the tips practical! It was definitely worth the late night to get those optimizations working smoothly for agentic workflows. Let me know how it goes when you try them out; I’d love to hear about your results!
Wow, staying up at 5 a.m. to test Qwen3 right after release—that’s some dedication! The throughput tips for the 4090 are super practical, especially the part about optimizing for agent-based workflows. Definitely trying these tweaks on my own setup this weekend.
Thanks so much for your kind words—I’m really glad you found the throughput tips practical! It was definitely worth the late night to get these insights out for the community. Let me know how the tweaks work on your setup; I’d love to hear about your results!