Transformer une seule photo en ville 3D avec l'outil de pinceau magique AI Ma Liang
L'université de Princeton, l'université Columbia et Cyberever AI ont conjointement présenté le cadre 3DTown, un outil révolutionnaire capable de générer des paysages urbains 3D réalistes à partir d'une seule vue aérienne. De manière remarquable, ce processus ne nécessite pas d'entraînement, car il utilise des générateurs d'objets 3D pré-entraînés pour donner vie à ces scènes vibrantes.
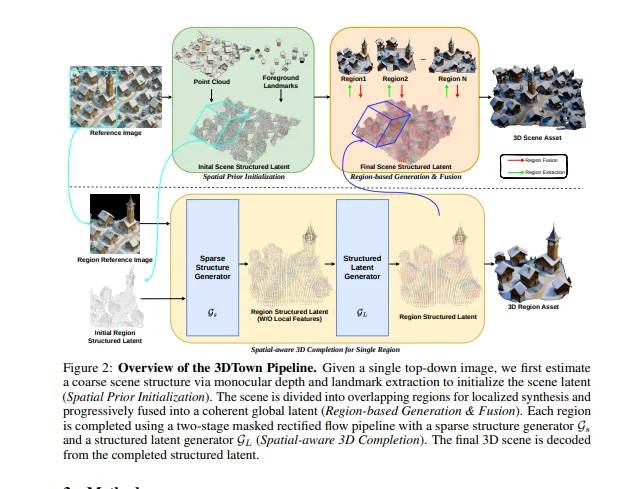
Le modélage 3D traditionnel a longtemps été entravé par des défis tels que l'équipement coûteux, les besoins importants de collecte de données et le travail manuel intensif qui demande à la fois du temps et de l'expertise. Bien que l'IA ait fait de grands progrès dans la génération d'objets 3D, elle peine souvent à gérer des scènes complexes, produisant des incohérences géométriques, des dispositions illogiques et une qualité de maillage inférieure.

3DTown surmonte ces limites grâce à une approche "diviser pour régner", en segmentant la vue aérienne en régions se chevauchant pour générer du contenu 3D pièce par pièce. Cette méthode améliore non seulement la résolution et les détails, mais assure également une alignement précis entre l'entrée image et sa contrepartie 3D. De plus, sa technologie de remplissage 3D spatialement consciente remplit de manière fluide les structures manquantes, préservant ainsi la continuité globale de la scène.
Les résultats expérimentaux montrent que 3DTown surpasse les modèles existants en termes d'exactitude géométrique, de cohérence de disposition et de fidélité des textures. Cette innovation présente un immense potentiel pour les applications dans le développement de jeux vidéo, la production cinématographique, la construction de métavers et même la formation de robots.
Malgré ses succès, 3DTown rencontre certaines limites. Par exemple, la dépendance aux générateurs pré-entraînés axés sur des objets individuels peut occasionnellement entraîner des inexactitudes localisées ou des "hallucinations". De plus, des vulnérabilités peuvent apparaître lors de l'estimation initiale de la structure 3D. Les progrès futurs pourraient inclure l'intégration de données multi-vues, l'introduction de priorités sémantiques ou la mise au point de niveau scène pour affiner davantage le cadre.
Article : https://arxiv.org/pdf/2505.15765 Projet : https://eric-ai-lab.github.io/3dtown.github.io/
Comments are closed.