Quand on exécute des modèles locaux, quelle est selon vous un délai de génération raisonnable pour les réponses ? Je suis curieux de savoir ce que d'autres considèrent comme des vitesses de traitement normales, en particulier lorsqu'il s'agit de trier le contexte, ce que je trouve être la partie la plus fastidieuse. Au moins avec une génération lente, on peut rester engagé en lisant la sortie au fur et à mesure qu'elle apparaît.
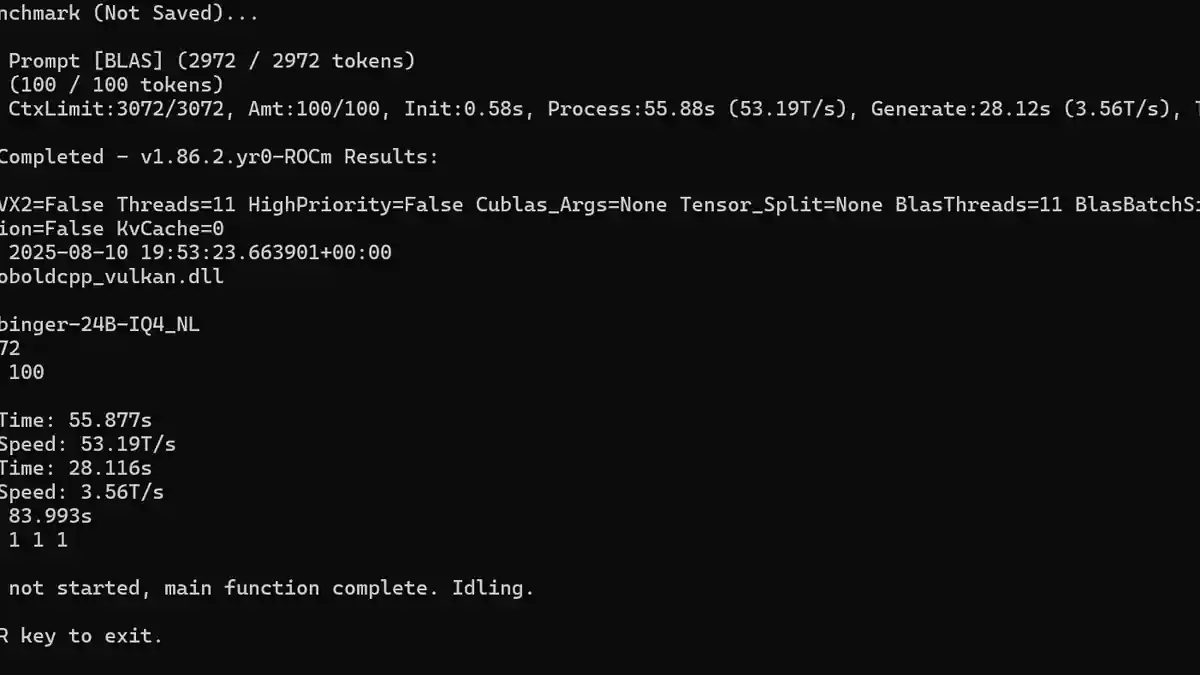
Pour moi, la vitesse de génération affichée sur la capture d'écran est à peu près aussi lente que je peux tolérer. J'ai expérimenté plusieurs modèles, généralement plus grands comme ceux avec 24-30 milliards de paramètres et certains modèles axés sur le raisonnement, où les tokens par seconde (T/s) descendaient autour de 14 T/s. Un modèle de raisonnement prenait régulièrement environ 10 minutes pour générer une réponse. Bien que la qualité soit généralement très bonne, je n'ai pas assez de patience pour le rôle de jeu à ce rythme.
Mon matériel comprend une RX 7900GRE, ce qui me met déjà en position d'inconvénient par rapport aux cartes Nvidia. J'ai constaté que les modèles avec entre 12 et 14 milliards de paramètres dans la plage de quantification q4 à q5 sont la limite de ce que mon ordinateur peut gérer raisonnablement bien, à moins que je ne passe à côté de paramètres ou de techniques d'optimisation cruciales pour améliorer les performances.