GPT-4.1 vs GPT-4o : Le dernier modèle d'IA d'OpenAI surpasse toutes les autres dimensions
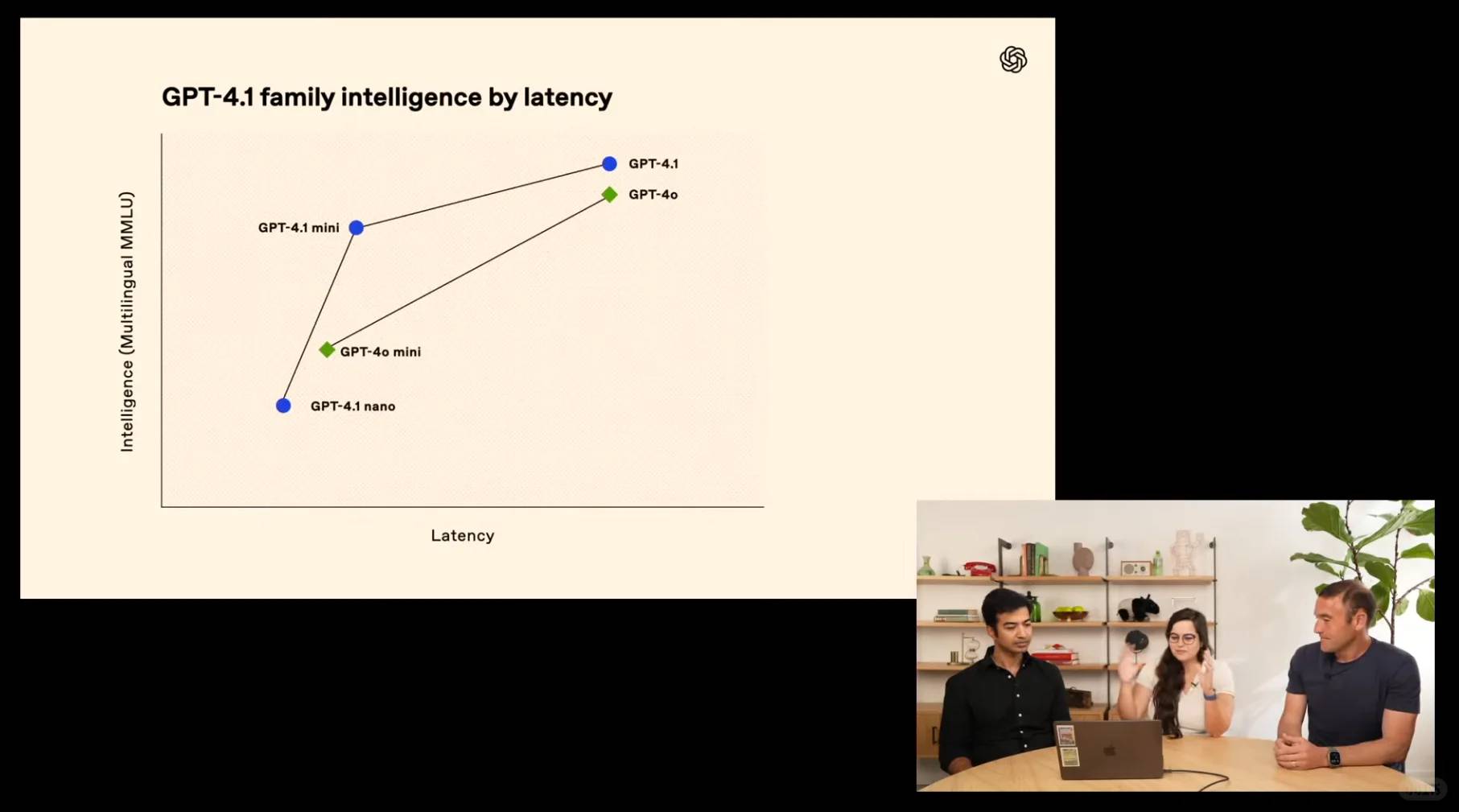
Présentation du trio révolutionnaire : GPT-4.1, GPT-4.1 mini et GPT-4.1 nano—dépassant leurs prédécesseurs avec des améliorations remarquables en matière de compétence en codage et d'exécution des instructions. Ces modèles de puissance disposent d'une fenêtre de contexte de 1 million de tokens, offrant une maîtrise sans précédent du contexte long. Observez comment GPT-4.1 domine les benchmarks industriels grâce à ses capacités de pointe :
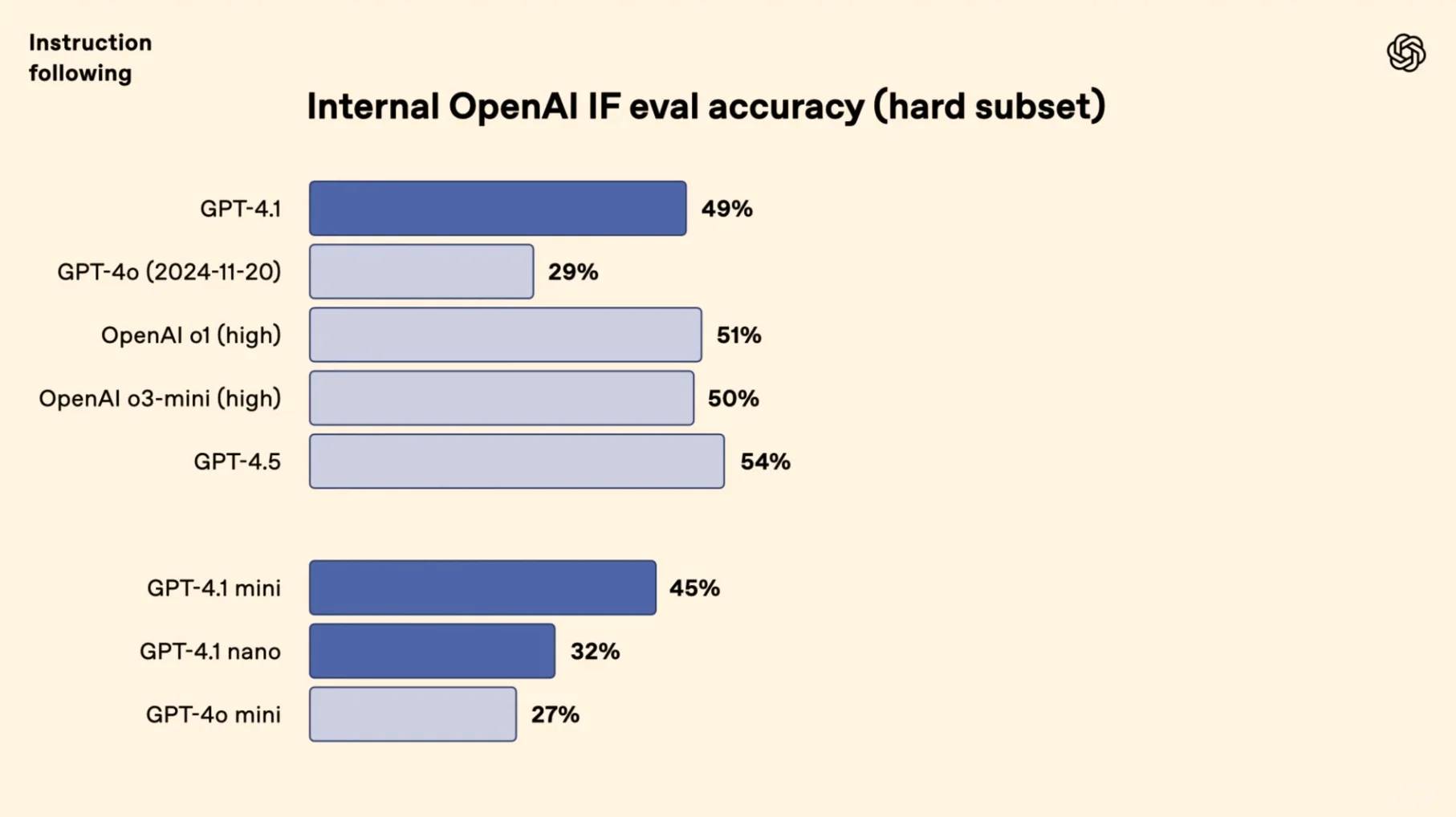
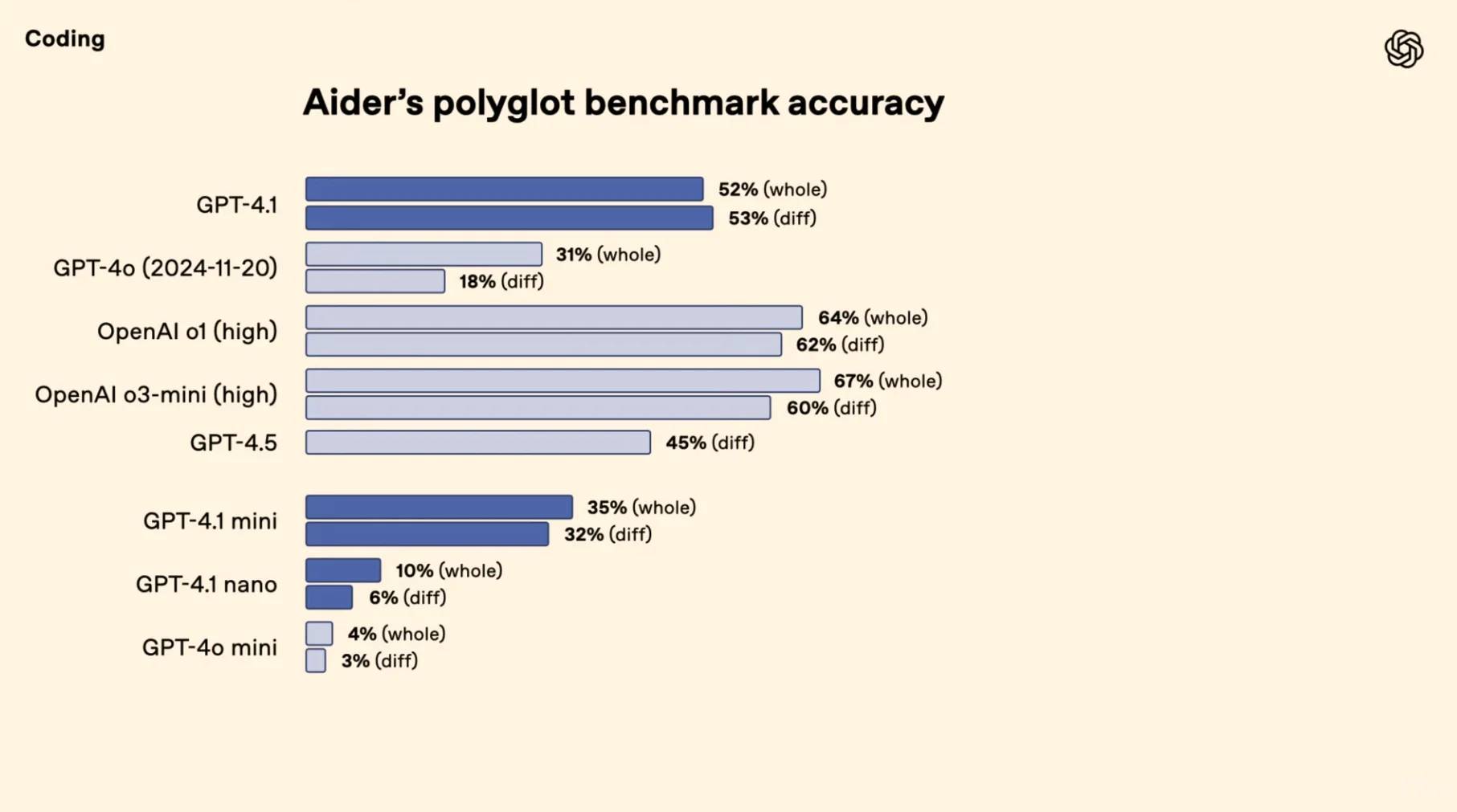
[🚀] **Maîtrise du Codage** : Écrasant la concurrence, GPT-4.1 atteint un taux de réussite impressionnant de 54,6 % sur SWE-bench—augmentant de 21,4 % par rapport à GPT-4o et de 26,6 % par rapport à GPT-4.5 pour revendiquer la couronne du codage. [🎯] **Exécution Précise** : Dans le cadre de Scale's MultiChallenge, GPT-4.1 atteint 38,3 %, montrant un bond de 10,5 % dans l'habileté à suivre les instructions par rapport à GPT-4o.
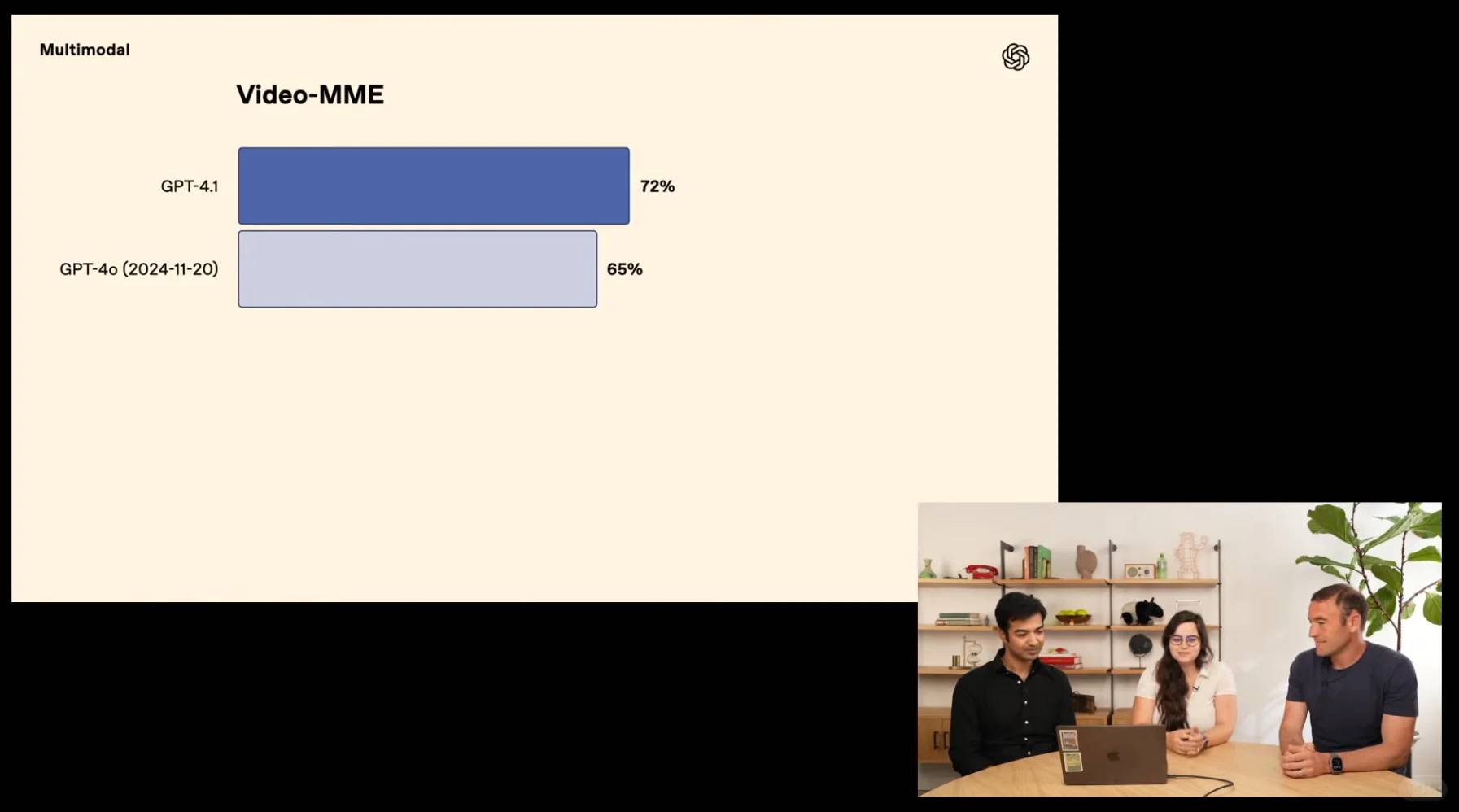
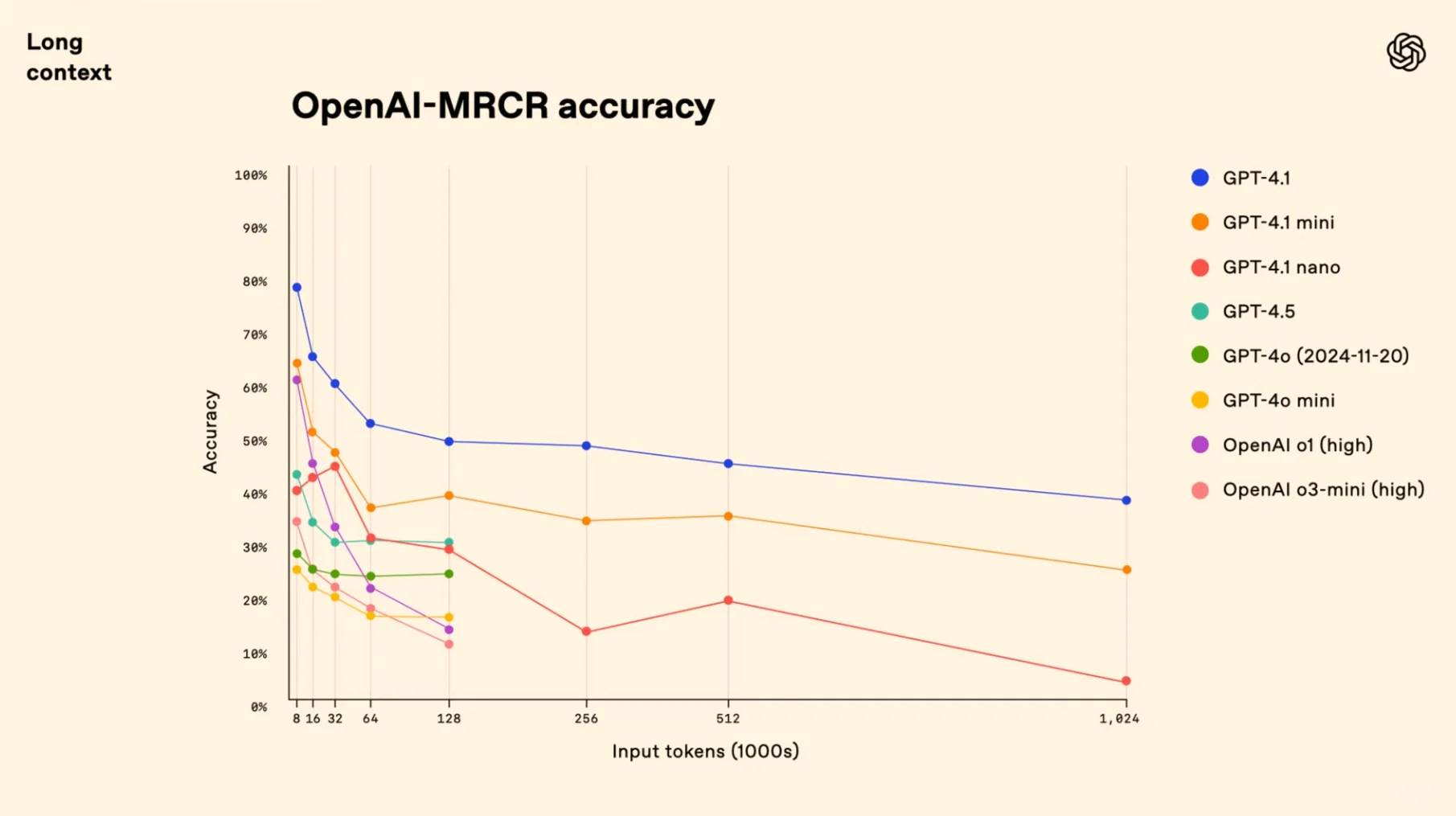
[🔍] **Champion du Contexte** : Réinventant les limites, GPT-4.1 obtient un score record de 72,0 % dans l'évaluation multimodale de Video-MME, surpassant GPT-4o de manière impressionnante de 6,7 %.

Je suis impressionné par les progrès de GPT-4.1, surtout en termes de précision dans l’exécution des instructions complexes. Le fait qu’il domine sur presque tous les benchmarks est assez incroyable, ça donne vraiment envie d’explorer ses capacités en profondeur.
Ces nouvelles versions de GPT semblent vraiment impressionnantes, surtout en termes de capacité à traiter du long texte et de surpasser les benchmarks existants. Je suis curieux de voir comment ces améliorations vont influencer l’utilisation pratique dans des projets réels, notamment pour le développement logiciel.
Wow, ces améliorations sur GPT-4.1 sont impressionnantes, surtout pour le codage ! J’ai hâte de tester la version nano pour voir si elle garde cette puissance dans un format plus léger. Ça promet des applications vraiment intéressantes pour les devs.
Merci pour votre enthousiasme ! La version nano conserve effectivement une grande partie des capacités de GPT-4.1, notamment pour le codage, tout en étant optimisée pour les appareils moins puissants. Je pense aussi que ça va révolutionner le workflow des développeurs. N’hésitez pas à nous faire part de votre retour après l’avoir testée !