Comment maximiser le débit de Qwen3 30B MOE sur une 4090 48G : Astuces et éclaircissements sur les performances
Oh mon Dieu, ce modèle semble avoir été conçu spécifiquement pour les Agents !
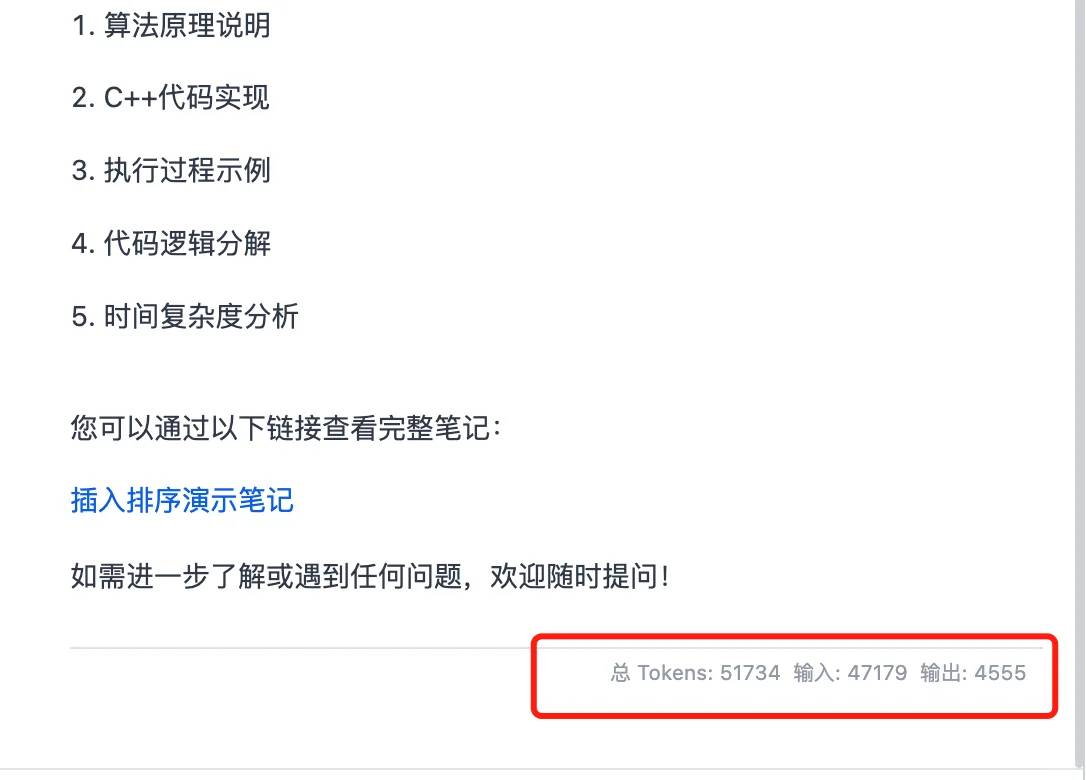
À 5 heures du matin, j'ai jeté un coup d'œil à mon téléphone et j'ai découvert que Qwen3 venait juste d'être publié. J'ai pensé retourner me coucher, mais l'excitation m'a empêché de dormir. Je savais que je devais plonger et le tester toute la journée.
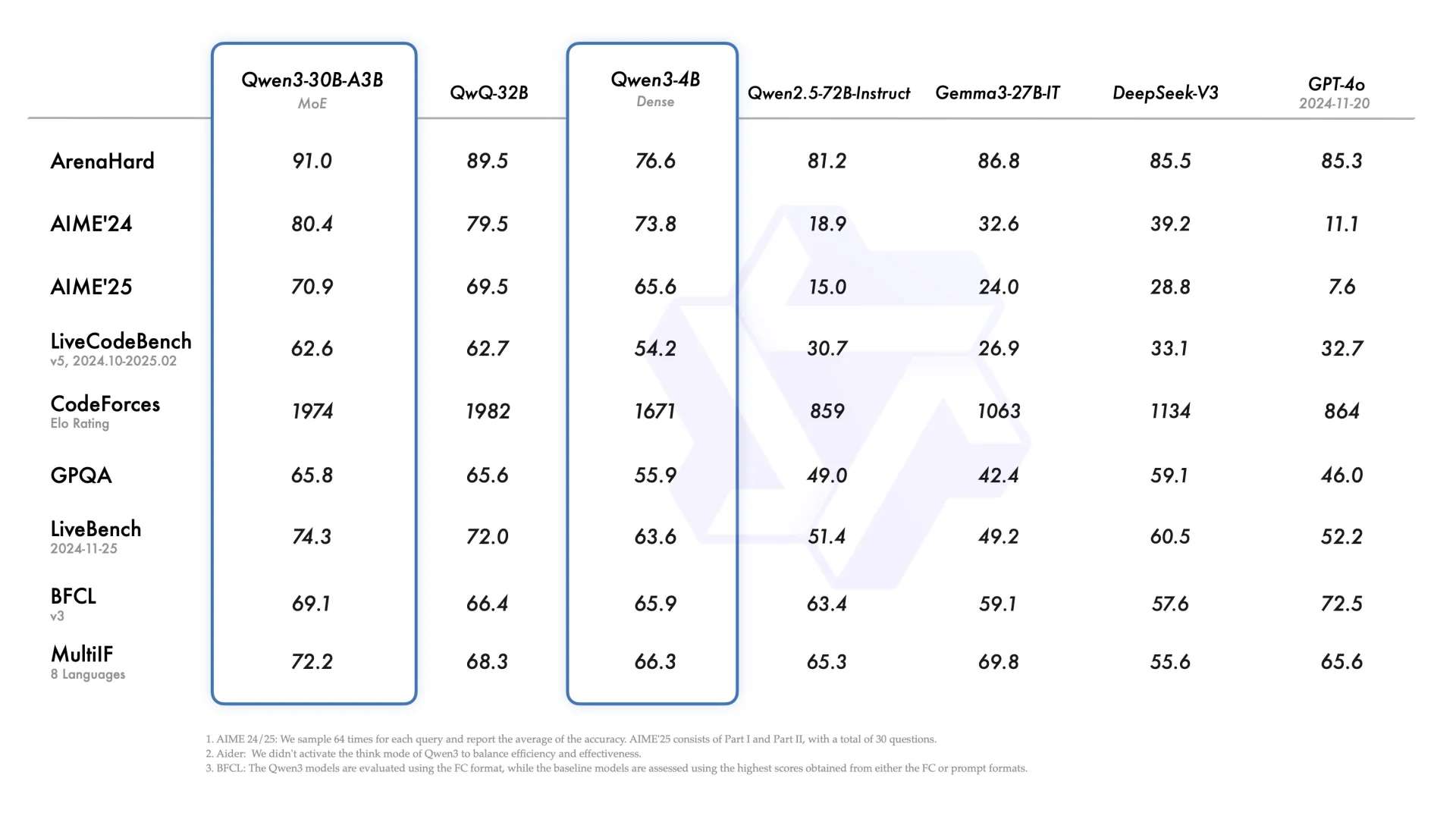
Lorsque j'ai vu pour la première fois Qwen3-30B-A3B, une pensée m'est immédiatement venue à l'esprit : cela pourrait très bien être un modèle conçu spécialement pour les Agents.
Actuellement, il existe deux défis majeurs lorsqu'il s'agit de mettre en œuvre des Agents : l'appel continu aux outils et la gestion de la consommation de tokens ainsi que de la vitesse.
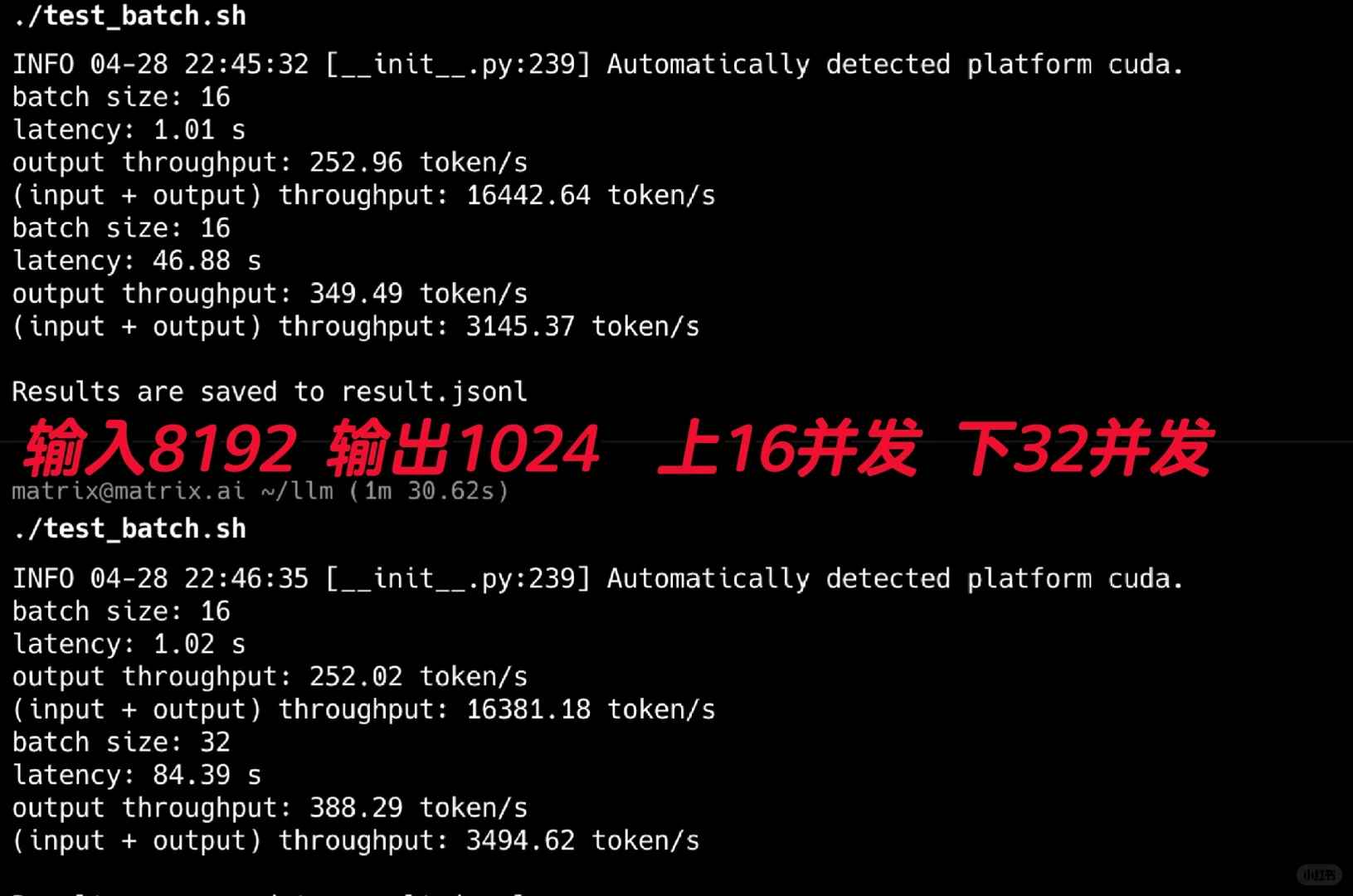
J'ai commencé par tester son débit, et les résultats étaient époustouflants ! J'ai utilisé la version FP8 pour ces tests. Comme indiqué dans la Figure 2, j'ai mené des tests simultanés de 16 et 32, simulant des scénarios typiques d'Agents avec des invites systèmes longues. En utilisant une entrée de 8192 et en définissant la sortie à 1024, il a atteint un impressionnant débit de sortie de 388t/s.
Gardez à l'esprit que cette performance a été obtenue sur une simple carte graphique 4090. Il semble que même les besoins internes d'un petit groupe d'Agents pourraient être couverts avec une ou deux 4090 en utilisant ce modèle.
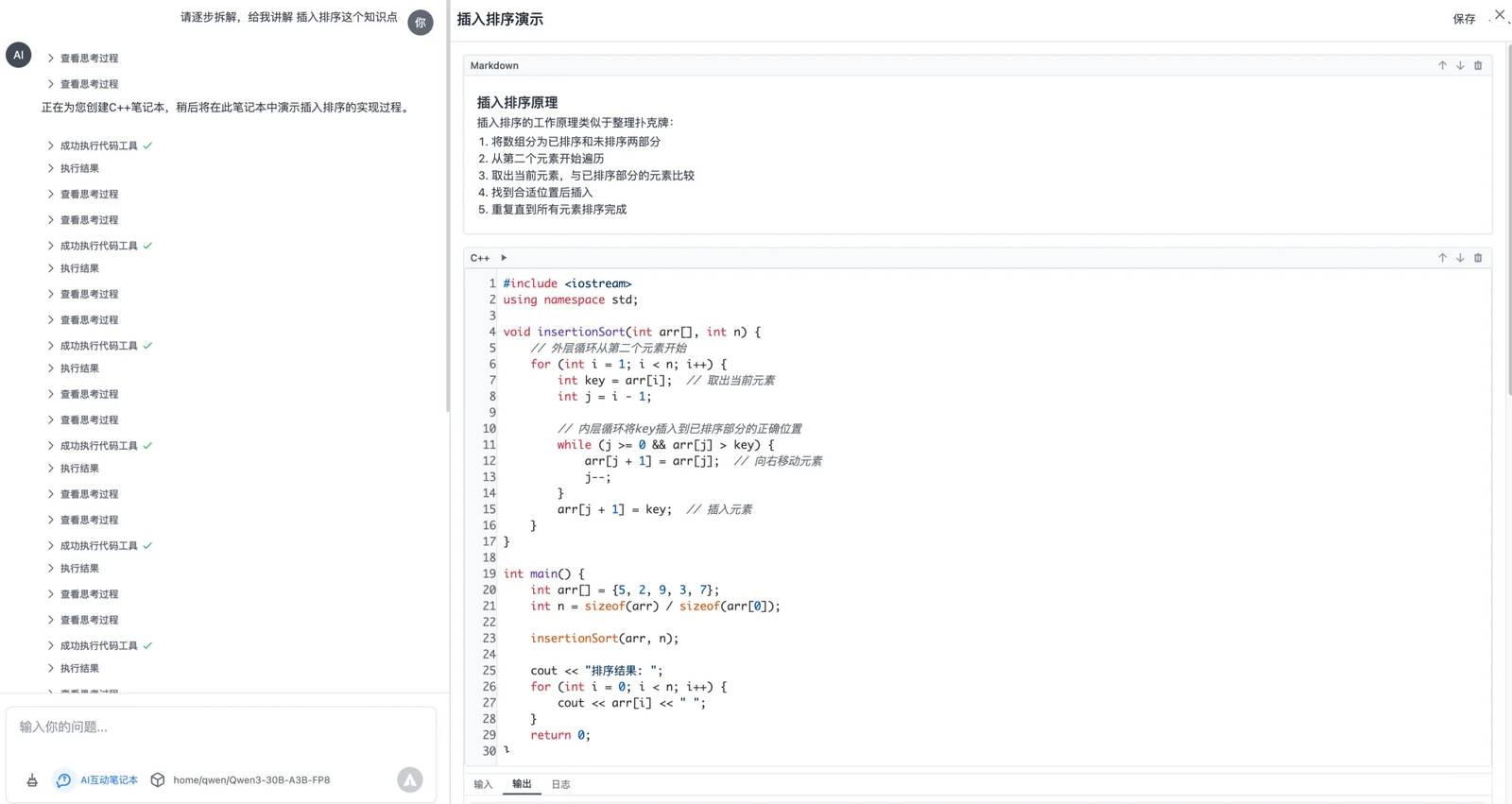
Ensuite, j'ai testé cela dans mon propre scénario spécifique. Mon assistant de résolution de problèmes en C++ est presque prêt pour les tests. Il utilise le protocole MCP pour créer un carnet interactif. Vous pouvez poser des questions en C++ à celui-ci, et il génère un carnet de code exécutable étape par étape, ce qui améliore considérablement l'efficacité d'apprentissage, surtout pour les enfants.
Ce scénario particulier implique plusieurs appels d'outils en plusieurs étapes, où l'IA opère et exécute continuellement des outils tout en analysant les résultats. Les résultats du test étaient tout simplement parfaits !
Dans chaque tour, le modèle évalue soigneusement l'état actuel de la tâche et détermine les prochaines étapes. Il est clair que ce modèle a été formé spécifiquement pour les tâches en plusieurs tours, et j'ai attendu quelque chose comme ça depuis un certain temps.
Ce qui m'a vraiment stupéfié, cependant, était le débit pour un utilisateur unique, qui dépassait 100t par seconde. Comme vous pouvez le voir dans ma dernière image, malgré la consommation de 50 000 tokens dans un scénario impliquant plusieurs tours d'utilisation d'outils, la vitesse de sortie était fulgurante, achevant tout le processus en seulement 40 secondes.
Le futur pourrait-il ressembler à cela : utiliser un MOE d'activation compact pour répondre aux préoccupations de vitesse et de coût, fournir des performances solides tout en traitant les problèmes les plus complexes dans les Agents ?
La patience a été récompensée. Dans les jours à venir, je continuerai à effectuer des tests approfondis sur ces modèles basés sur mon scénario d'Agent d'apprentissage en C++. De plus, concernant ce modèle de 200B+, je crois qu'il pourrait être possible de le faire fonctionner sur une seule machine avec un ajustement fin en utilisant Ktransformer. Y a-t-il quelqu'un d'intéressé ? Si oui, je serais heureux de mener davantage de tests.
J’ai essayé ces astuces avec mon 4090 et franchement, la différence est impressionnante ! Réduire la taille des baches et optimiser les batchs multiples m’a permis d’augmenter significativement le débit. C’est incroyable de voir à quel point les ajustements techniques peuvent avoir un impact. Je suis content d’avoir testé tout ça dès le lancement à 5h du matin !
Super intéressant ! J’ai essayé quelques trucs avec Qwen3 sur mon 4090 et tes conseils sur l’optimisation de la throughput sont clairement les bons. Je n’avais pas pensé à ajuster ces paramètres, ça change tout !