Wie man die Qwen3 30B MOE-Throughput auf einer 4090 48G maximiert: Tipps & Performance-Einblicke
Oh mein Gott, dieser Modell fühlt sich an, als wäre er speziell für Agenten entwickelt worden!
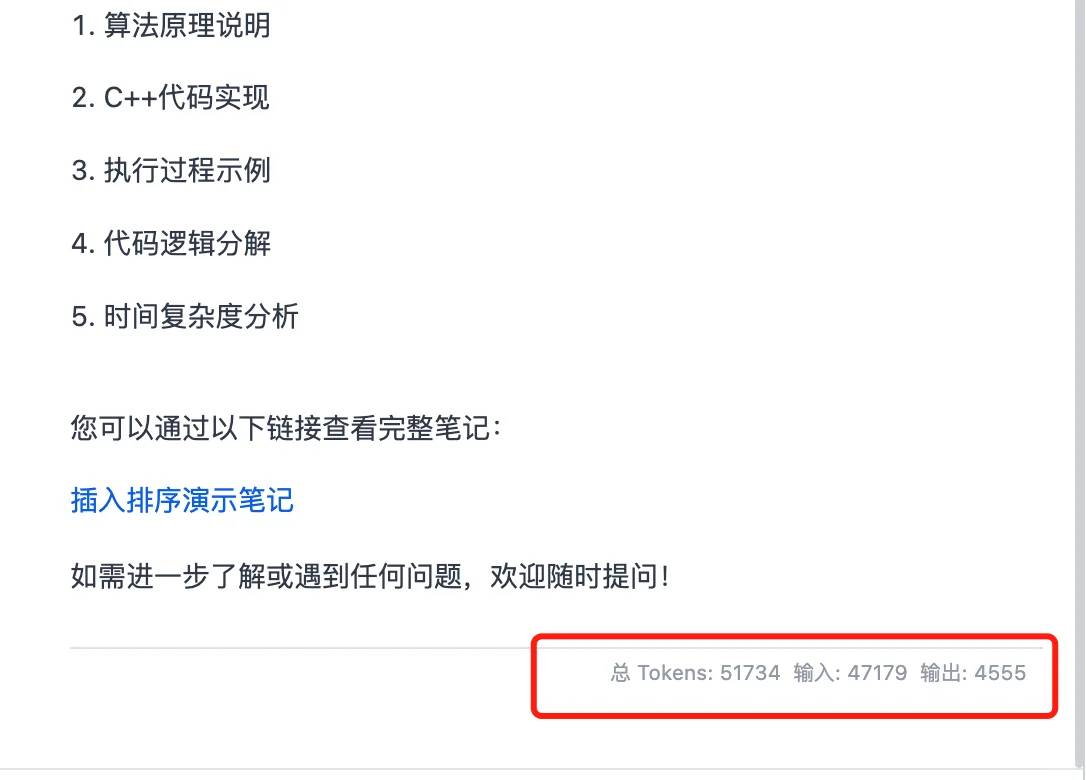
Gegen 5 Uhr morgens warf ich einen Blick auf mein Telefon und stellte fest, dass Qwen3 gerade veröffentlicht worden war. Ich dachte daran, wieder einzuschlafen, aber die Aufregung hielt mich wach. Ich wusste, dass ich mich hineinstürzen und es den ganzen Tag lang testen musste.
Als ich das erste Mal Qwen3-30B-A3B sah, schoss mir sofort ein Gedanke durch den Kopf: Dies könnte sehr wohl ein Modell sein, das speziell für Agenten konzipiert wurde.
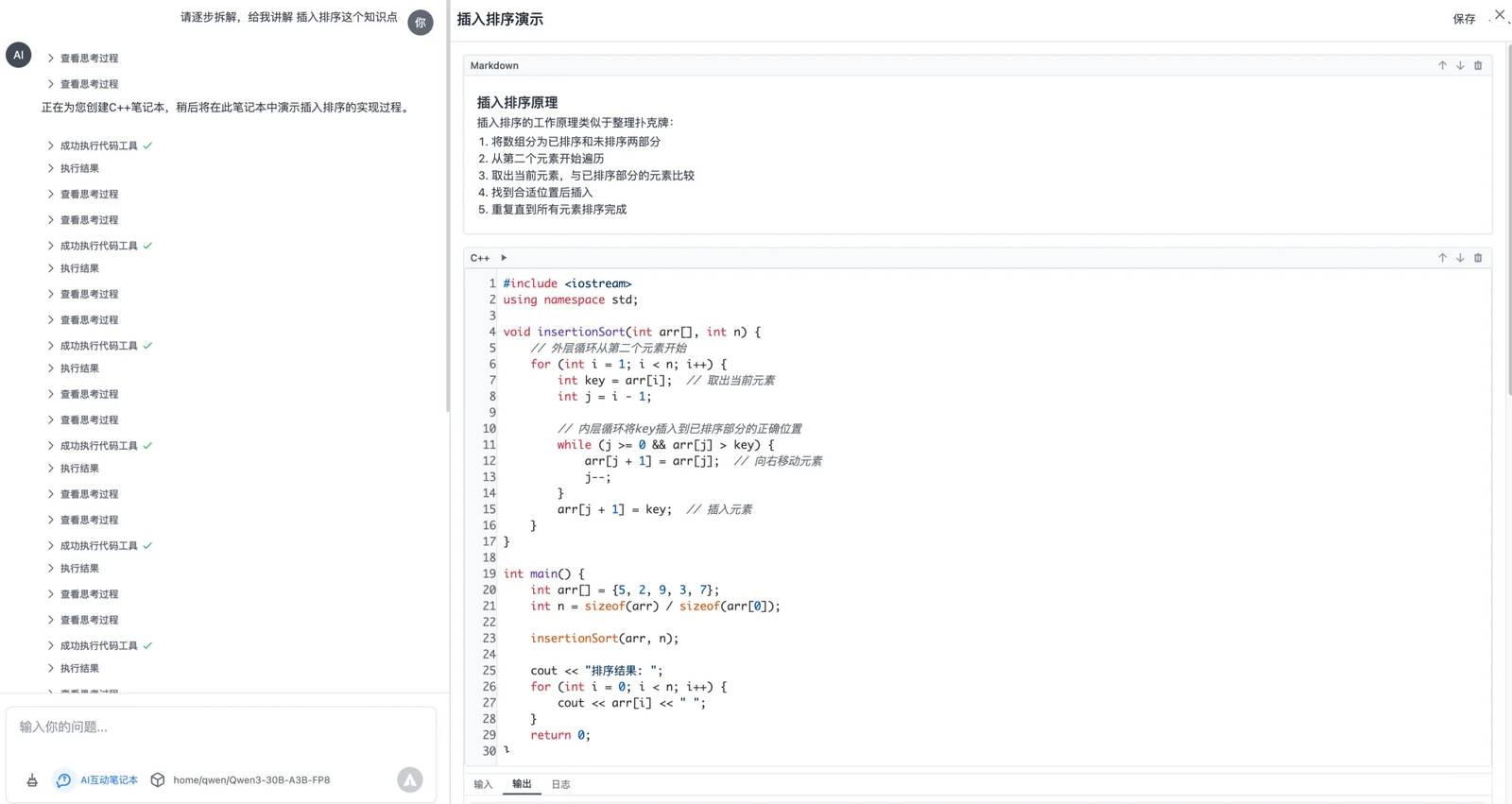
Bisher gibt es zwei bedeutende Herausforderungen bei der Implementierung von Agenten: kontinuierliche Werkzeugaufrufe und die Verwaltung des Tokenverbrauchs zusammen mit der Geschwindigkeit.
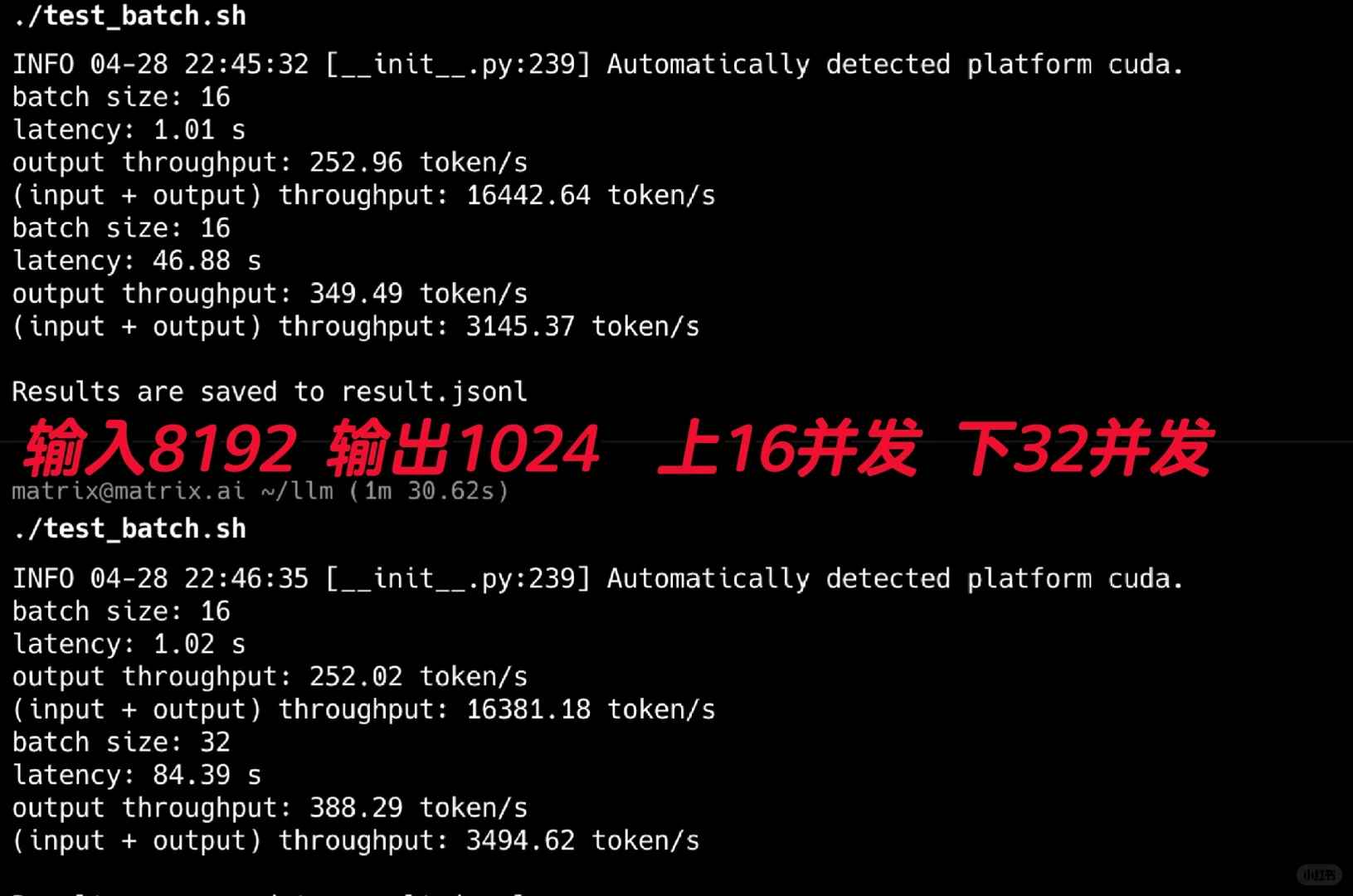
Ich begann mit dem Test der Durchsatzleistung, und die Ergebnisse waren atemberaubend! Für diese Tests verwendete ich die FP8-Version. Wie in Abbildung 2 gezeigt, führte ich 16 und 32 gleichzeitige Tests durch, um typische Agentenszenarien mit langen Systemprompts zu simulieren. Mit einer Eingabe von 8192 und einer Ausgabe von 1024 erreichte es eine beeindruckende Ausgabedurchsatzrate von 388t/s.
Beachten Sie, dass diese Leistung auf nur einer 4090-GPU erreicht wurde. Es scheint, dass selbst die internen Agentenanforderungen einer kleinen Firma mit nur einer oder zwei 4090er-GPUs mit diesem Modell erfüllt werden könnten.
Nächstes teste ich es unter meinen eigenen spezifischen Szenario. Mein C++-Problemlöser-Assistent ist fast bereit für Tests. Er nutzt das MCP-Protokoll, um ein interaktives Notizbuch zu erstellen. Man kann ihm C++-Fragen stellen, und es generiert ein schrittweises ausführbares Code-Notizbuch, was den Lerneffizienz erheblich verbessert, insbesondere für Kinder.
Dieses spezifische Szenario umfasst mehrere Runden von Werkzeugaufrufen, bei denen die KI kontinuierlich Werkzeuge ausführt und analysiert, während sie die Ergebnisse verarbeitet. Die Testergebnisse waren nichts weniger als perfekt!
In jeder Runde bewertet das Modell sorgfältig den aktuellen Aufgabenstatus und bestimmt die nächsten Schritte. Offensichtlich wurde dieses Modell speziell für mehrstufige Aufgaben trainiert, und ich habe schon seit einer Weile darauf gewartet, etwas Derartiges zu sehen.
Was mich jedoch wirklich überraschte, war die Einzelbenutzer-Durchsatzleistung, die über 100t pro Sekunde betrug. Wie Sie in meinem letzten Bild sehen können, trotz eines Tokenverbrauchs von 50.000 in einem Szenario mit mehreren Runden von Werkzeugnutzung, war die Ausgabegeschwindigkeit blitzschnell und vollständig innerhalb von 40 Sekunden abgeschlossen.
Könnte die Zukunft so aussehen: die Nutzung eines kompakten Aktivierungsmodus MOE, um sowohl Geschwindigkeit als auch Kosten zu adressieren, während dabei solide Leistungen bei der Lösung der komplexesten Probleme in Agenten geliefert werden?
Die Wartezeit hat sich absolut gelohnt. In den kommenden Tagen werde ich weiterhin tiefgehende Tests dieser Modelle basierend auf meinem C++-Lern-Agentenszenario durchführen. Außerdem bezüglich jenes 200B+-Modells glaube ich, dass es mit ein wenig Fine-Tuning mit Ktransformer auf einem einzelnen Rechner ausgeführt werden könnte. Ist jemand interessiert? Wenn ja, würde ich gerne weitere Tests durchführen.
Wow, the tips in this article really helped me optimize my setup! I didn’t realize adjusting the batch size could make such a big difference. Gotta say, the performance insights were eye-opening. Time to tweak my configurations and see how much further I can push it!
Vielen Dank für dein Feedback! Es freut mich zu hören, dass die Tipps hilfreich waren – der Batch-Size-Adjustment ist tatsächlich ein Game-Changer. Experimentiere gerne weiter mit den Einstellungen, da noch mehr Optimierungspotential oft im Detail liegt. Herzlichen Dank für deine Engagement und viel Erfolg beim Tweaken! 😊