Wandle Einzelne Fotos mit dem AI-Zaubermalwerkzeug Ma Liang in 3D-Städte um
Die Princeton University, die Columbia University und das Cyberever AI haben gemeinsam das 3DTown-Framework vorgestellt – ein bahnbrechendes Werkzeug, das realistische 3D-Stadtlandschaften aus einer einzigen Vogelperspektive generieren kann. Bemerkenswerterweise erfordert dieser Prozess keine spezielle Schulung, da es auf vortrainierten 3D-Objektgeneratoren basiert, um diese lebhaften Szenen zum Leben zu erwecken.
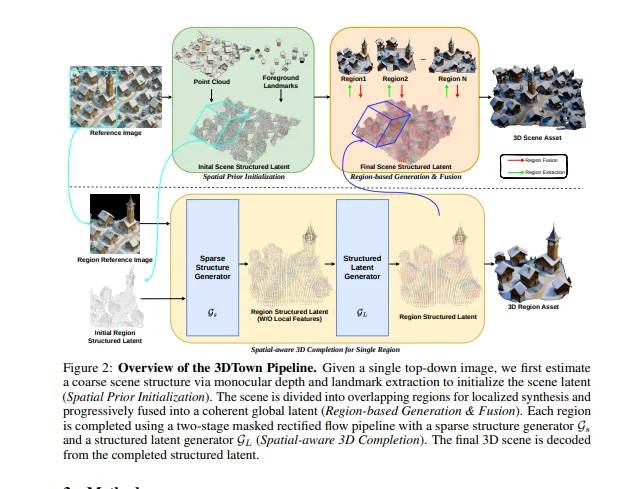
Traditionelles 3D-Modellieren wurde lange durch Herausforderungen wie teure Ausrüstung, umfangreiche Datenerfassungsbedarf und arbeitsintensive manuelle Arbeit behindert, die sowohl Zeit als auch Expertise erfordern. Während AI in der Generierung von 3D-Objekten große Fortschritte gemacht hat, scheitert es oft bei der Bewältigung komplexer Szenen, wodurch Geometrieunstimmigkeiten, logisch inkonsistente Layouts und mangelnde Mesh-Qualität entstehen.

3DTown überwindet diese Mängel mit einem „Teile und Herrsche“-Ansatz, indem es die Vogelperspektive in überlappende Regionen unterteilt, um 3D-Inhalte stückchenweise zu generieren. Diese Methode verbessert nicht nur Auflösung und Detailgenauigkeit, sondern sorgt auch für eine genaue Übereinstimmung zwischen dem Bildinput und dessen 3D-Gegenstück. Darüber hinaus füllt seine raumorientierte 3D-Einfügungstechnologie fehlende Strukturen nahtlos aus, wodurch die Gesamtstetigkeit der Szene erhalten bleibt.
Experimentelle Ergebnisse zeigen, dass 3DTown im Hinblick auf geometrische Genauigkeit, Layout-Kohärenz und Texturtreue bestehende Modelle übertrifft. Diese Innovation birgt großes Potenzial für Anwendungen in der Computerspielentwicklung, Filmproduktion, Metavers-Konstruktion und sogar in der Roboter-Simulationstrainings.
Obwohl 3DTown beachtliche Errungenschaften vorweisen kann, hat es bestimmte Grenzen. So kann beispielsweise die Abhängigkeit von vortrainierten Generatoren, die sich auf einzelne Objekte konzentrieren, gelegentlich zu lokalisierten Ungenauigkeiten oder „Halluzinationen“ führen. Zudem können Schwachstellen auftreten beim ersten groben Schätzen der 3D-Struktur. Zukünftige Verbesserungen könnten die Integration von Mehrblickdaten, die Einführung semantischer Vorannahmen oder die Szeneebene-Fine-Tuning beinhalten, um das Framework weiter zu optimieren.
Dokumentation: https://arxiv.org/pdf/2505.15765 Projekt: https://eric-ai-lab.github.io/3dtown.github.io/
Wow, das klingt ja nach einem echten Game-Changer für 3D-Modellierung! Besonders beeindruckend finde ich, dass das Tool ohne Training auskommt und trotzdem so detaillierte Ergebnisse liefert. Kann mir gut vorstellen, wie das Architekten oder Game-Designer total den Arbeitsalltag erleichtern könnte.