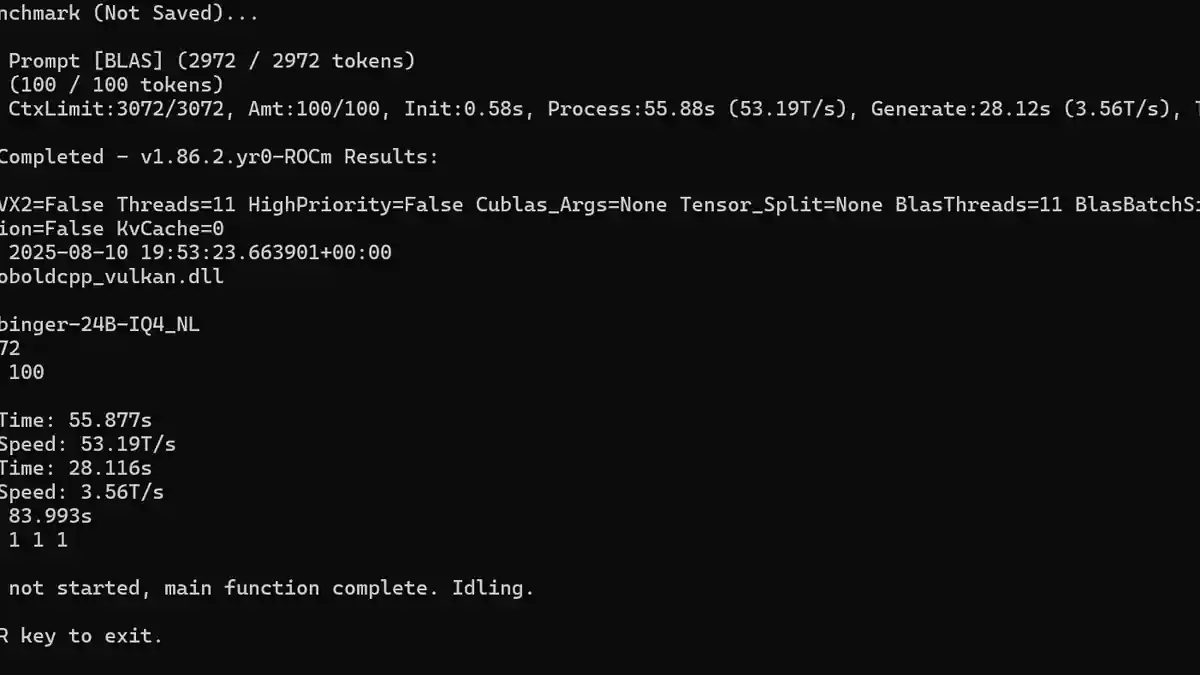
Wenn man lokale Modelle ausführt, was halten Sie für eine angemessene Generierungszeit für Antworten? Ich bin neugierig darauf, was andere als normale Verarbeitungsgeschwindigkeiten betrachten, insbesondere wenn es darum geht, durch den Kontext zu sichten, was ich als die mühsamste Aufgabe finde. Zumindest bei langsamer Generierung kann man sich weiterhin engagieren, indem man den Output liest, während er allmählich erscheint.
Für mich ist die Generierungsgeschwindigkeit, die im Screenshot gezeigt wird, etwa so langsam, wie ich es ertragen kann. Ich habe mehrere Modelle getestet, meist größere Modelle mit 24-30B Parametern und einige modellbasierte Reasoning-Modelle, bei denen die Tokens pro Sekunde (T/s) auf etwa 14 T/s sanken. Ein Reasoning-Modell benötigte regelmäßig etwa 10 Minuten, um eine Antwort zu generieren. Obwohl die Qualität allgemein sehr gut war, bin ich nicht geduldig genug, um bei dieser Geschwindigkeit Rollenspiele zu betreiben.
Meine Ausrüstung besteht aus einer RX 7900GRE, was mich bereits in Nachteil gegenüber Nvidia-Karten bringt. Ich habe festgestellt, dass Modelle mit 12B bis 14B Parametern im Quantisierungs Bereich q4 bis q5 die Grenze dessen sind, was mein System vernünftig verarbeiten kann, es sei denn, ich übersehe einige entscheidende Einstellungen oder Optimierungstechniken, um die Leistung zu verbessern.