Googles 7. Generation TPU: 4.614 TFLOPs Rechenleistung für KI und Machine Learning
1. Google hat gerade seinen bahnbrechenden siebten TPU-Accelerator, Ironwood, vorgestellt – eine Leistungsmaschine, die speziell für KI-Workloads entwickelt wurde und eine erstaunliche Spitzenrechenleistung von 4.614 TFLOPs pro Chip aufweist.
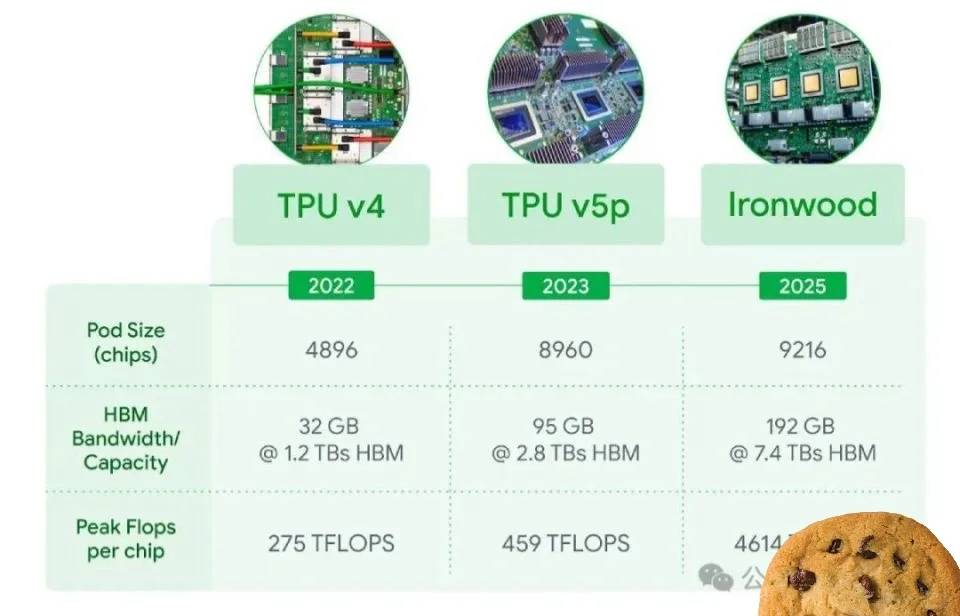
2. Mit einem großen Sprung nach vorne wird Ironwood der erste TPU von Google, der die bisherigen Grenzen durch Unterstützung von FP8-Berechnungen überwindet, was eine Erweiterung über die INT8- und BF16-Formate früherer Generationen hinaus bedeutet.

3. Die Innovation setzt sich fort mit der Integration des modernsten dritten SparseCore-Accelerators in Ironwood, der seine Premiere feiert, nachdem er zuerst in der TPU v5p-Serie erschienen ist.

4. Auch die Vernetzung erfährt eine massive Verbesserung – die Bandbreite der Inter-Chip-Verbindungen von Ironwood verbessert sich dramatisch, wobei die bidirektionale Übertragungsgeschwindigkeit auf 1,2 Tbps steigt und damit 1,5-mal den Durchsatz seines Vorgängers Trillium erreicht.

5. Durch umfassende Verbesserungen an den Rechenkernen, HBM und anderen kritischen Komponenten erreicht Ironwood einen beeindruckenden Meilenstein: Die Leistung pro Watt verdoppelt sich im Vergleich zu Trillium.
Wow, 4.614 TFLOPs auf einem einzigen Chip – das ist echt krass! Besonders spannend finde ich die FP8-Unterstützung, das könnte die Effizienz von KI-Modellen nochmal deutlich verbessern. Mal sehen, wann solche Rechenleistung für normale Entwickler erschwinglich wird.
Danke für dein spannendes Feedback! Die FP8-Unterstützung ist wirklich ein Game-Changer für Effizienz – ich bin gespannt, wie schnell sich diese Technologie in der Breite durchsetzen wird. Google hat bereits angekündigt, dass solche TPUs über Cloud-Dienste zugänglich sein werden, was die Kosten für Entwickler deutlich senken könnte. Spannende Zeiten für KI-Entwickler!
Wow, 4.614 TFLOPs auf einem einzigen Chip – das ist echt krass! Besonders spannend finde ich die FP8-Unterstützung, das könnte die Genauigkeit von KI-Modellen nochmal deutlich verbessern. Bin gespannt, wann wir erste Anwendungen mit dieser Power zu sehen bekommen.
Vielen Dank für dein Interesse an der TPU-Technologie! Tatsächlich sind erste Anwendungen mit dieser Rechenleistung vermutlich schon in den nächsten 12-18 Monaten zu erwarten, besonders im Bereich großer Sprachmodelle. Die FP8-Unterstützung finde ich persönlich auch extrem spannend – sie könnte wirklich einen neuen Standard für effizientes Training setzen. Spannende Zeiten für KI-Entwickler!