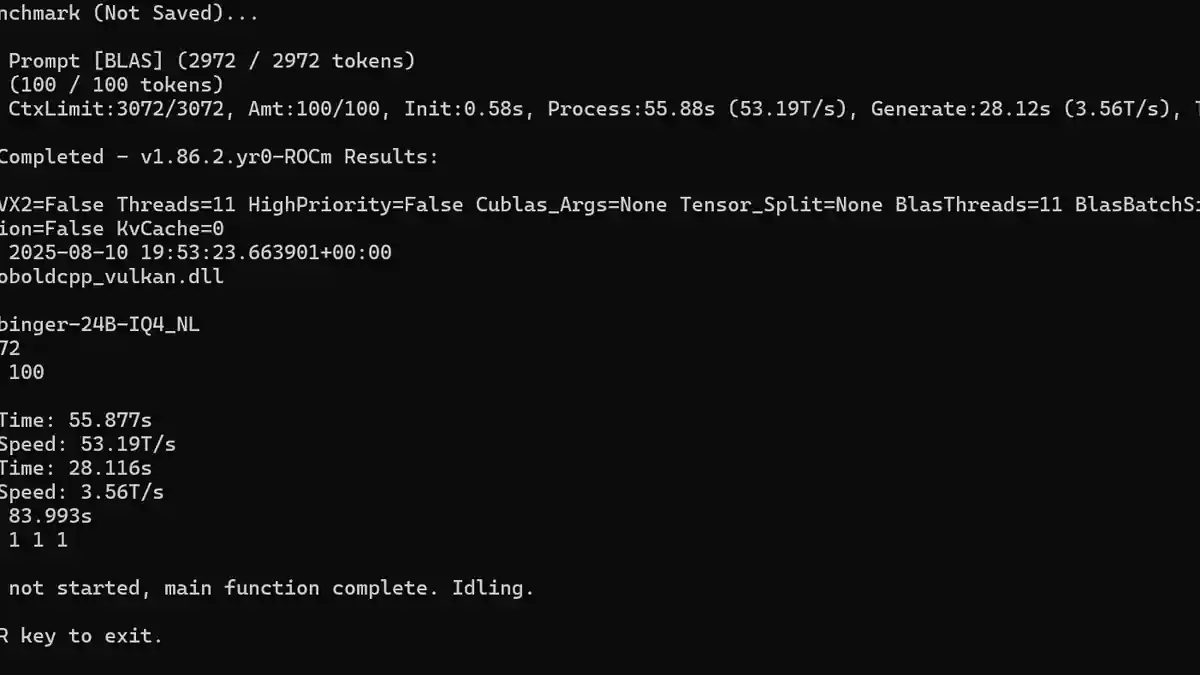
عند تشغيل النماذج المحلية، ما الذي تراه زمنًا معقولًا لتصنيع الإجابات؟ أود معرفة ما يراه الآخرون كسرعات معالجة طبيعية، خاصة عند التصفية من خلال السياق، وهو الجزء الذي أجد أنه أكثر إرهاقًا. على الأقل مع التصنيع البطيء، يمكنك البقاء مهتمًا بالقراءة بينما تظهر النتيجة تدريجيًا.
بالنسبة لي، سرعة التصنيع الموضحة في الصورة هي بطيئة إلى حد يكاد يكون مقبولًا. لقد جرّبت عدة نماذج، عادةً نماذج أكبر مثل 24-30 مليار معلمة ونموذجين مركّزين على الاستنتاج، حيث تنخفض عدد الرموز لكل ثانية (T/s) إلى حوالي 14 T/s. نموذج استنتاج واحد كان يستغرق حوالي 10 دقائق لإنشاء إجابة. على الرغم من أن الجودة كانت عادةً جيدة جدًا، إلا أنني لا أملك الصبر الكافي للعب أدوار بمثل هذه السرعة.
تتضمن معداتي RX 7900GRE، والتي تضعني بالفعل في موقف غير مواتٍ مقارنة ببطاقات Nvidia. وجدت أن النماذج التي تتراوح معلماتها بين 12B إلى 14B ضمن نطاق التكميم q4 إلى q5 هي الحد الأقصى لما يمكن لجهازي التعامل معه بشكل معقول، إلا إذا كنت أتجاهل بعض الإعدادات أو تقنيات التحسين المهمة لتحسين الأداء.