كيفية تحسين معدل عبور Qwen3 30B MOE على بطاقات رسوميات RTX 4090 48G: نصائح ورؤى الأداء
يا له من روعة، يبدو أن هذا النموذج قد تم صنعه خصيصًا للعملاء!
في الساعة الخامسة صباحًا، التفت إلى هاتفي واكتشفت أن Qwen3 قد تم إصداره للتو. فكرت في العودة إلى النوم، لكن الحماس أبقاني مستيقظًا. علمت أنني بحاجة إلى الغوص فيه واختباره طوال اليوم.
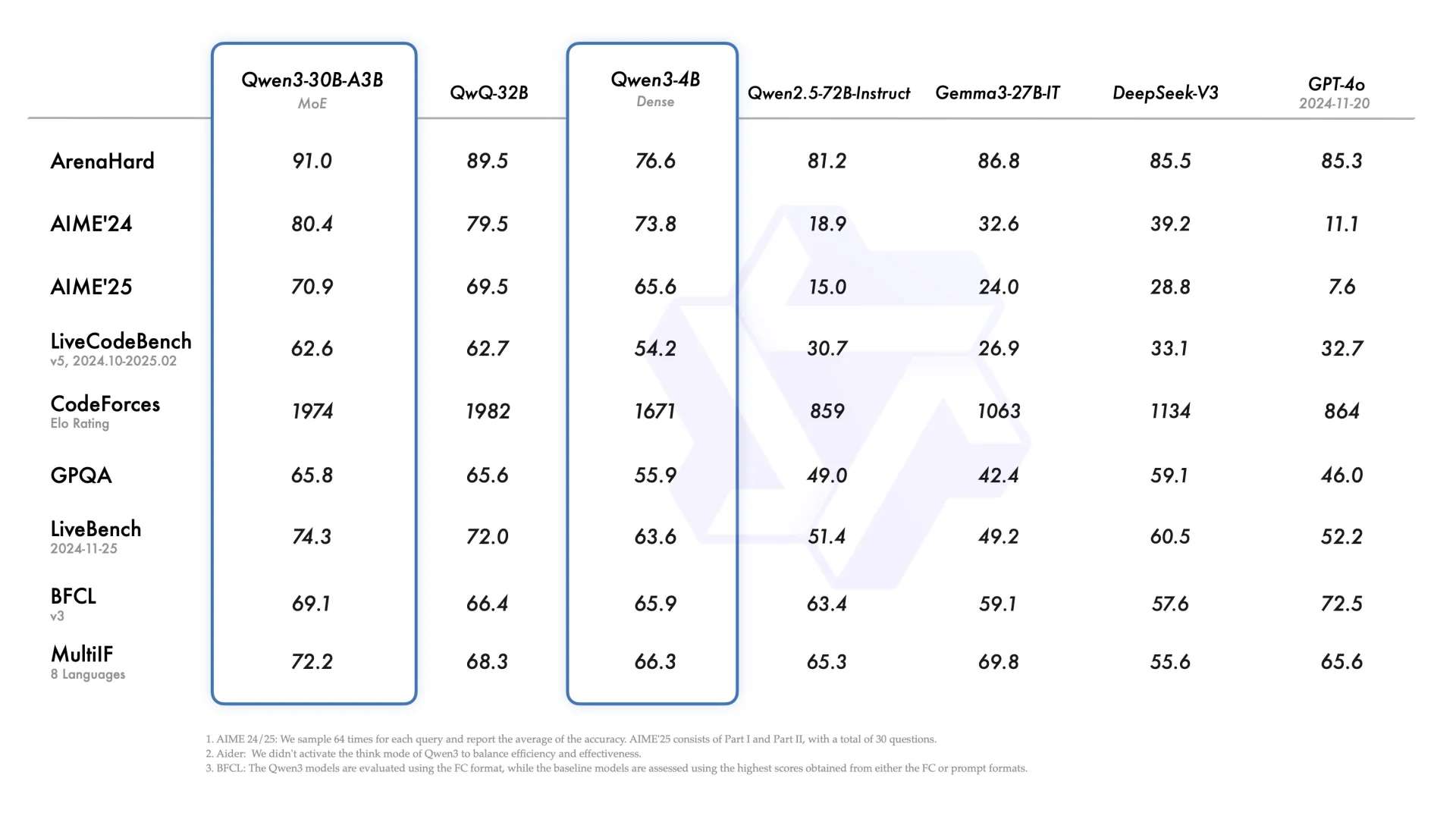
عندما رأيت لأول مرة Qwen3-30B-A3B، خطرت لي فكرة فورية: يمكن أن يكون هذا النموذج مصممًا خصيصًا للعملاء.
حالياً، هناك تحديان كبيران عندما يتعلق الأمر بتنفيذ العملاء: استدعاء الأدوات المستمر وإدارة استهلاك الرموز مع السرعة.
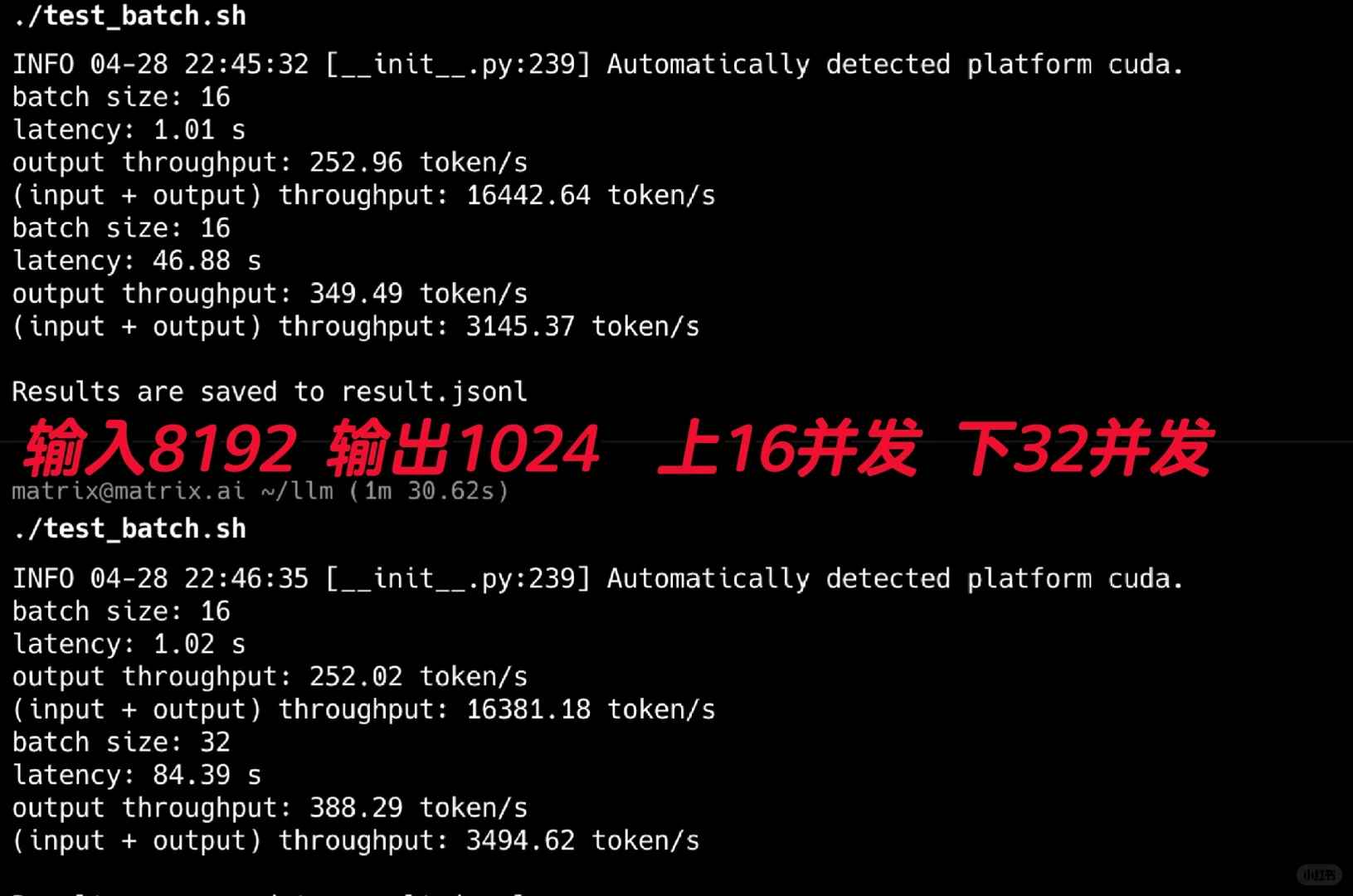
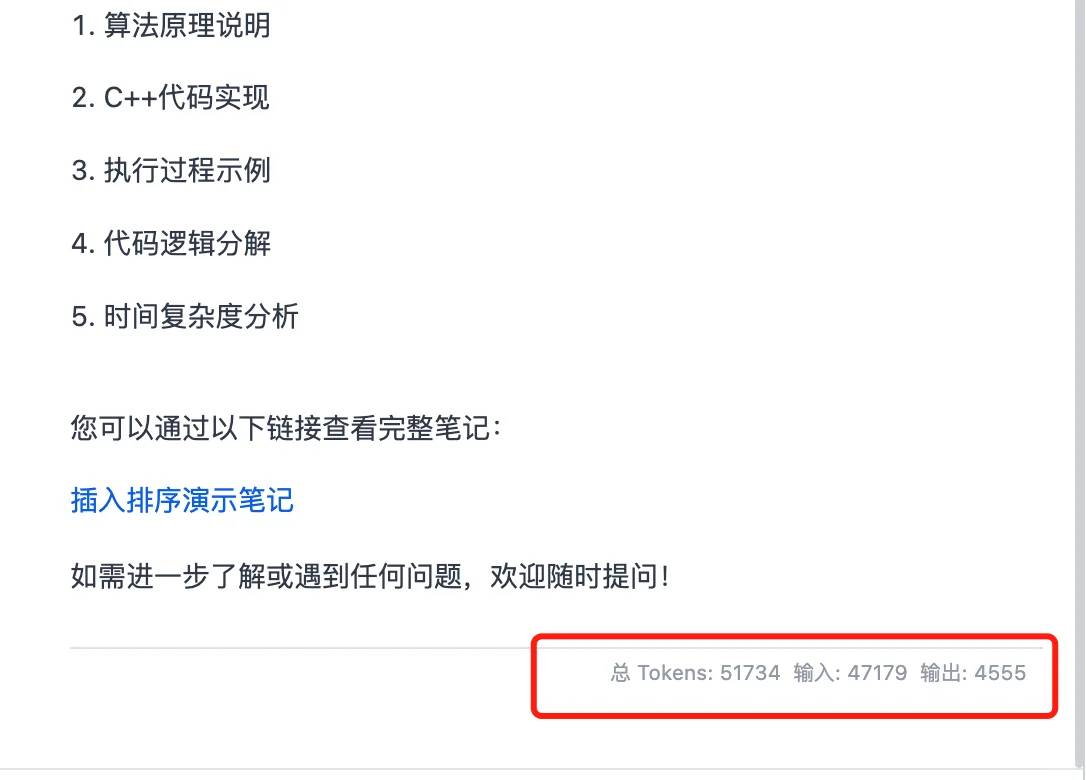
بدأت باختبار معدل العبور الخاص به، وكانت النتائج مذهلة! استخدمت الإصدار FP8 لهذه الاختبارات. كما هو موضح في الشكل 2، أجريت اختبارات متزامنة بـ 16 و32 عملية، واستعرت سيناريوهات العميل العادية باستخدام أوامر نظام طويلة. باستخدام مدخلات بحجم 8192 وضبط المخرجات على 1024، حقق معدل عبور مذهل بلغ 388t/s.
تذكر، تم تحقيق هذه الأداءات على بطاقة رسوميات واحدة فقط من نوع RTX 4090. يبدو أن حتى متطلبات العملاء الداخلية لشركات صغيرة يمكن تلبيتها باستخدام هذا النموذج وباستخدام بطاقة أو اثنتين من RTX 4090.
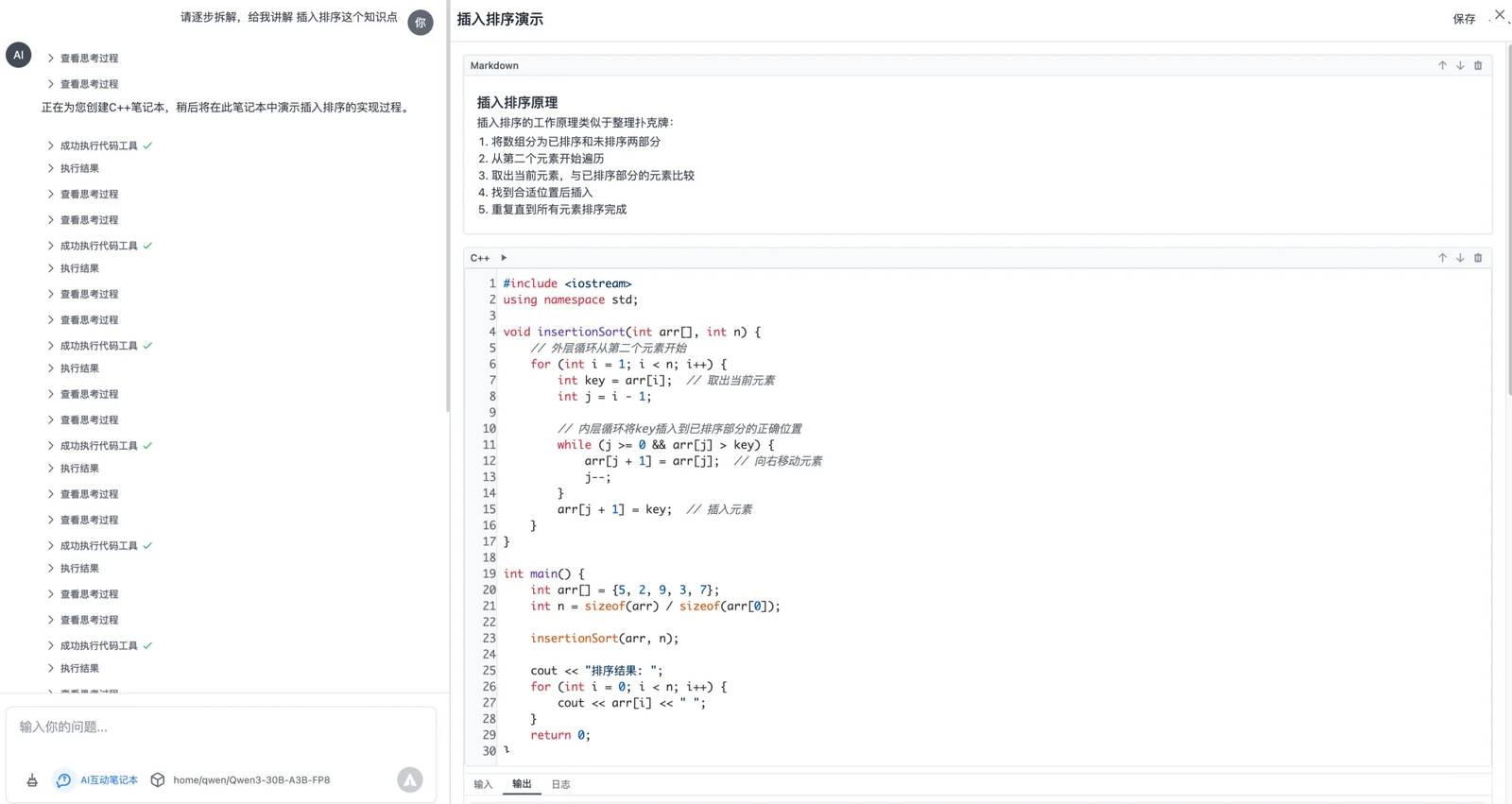
بعد ذلك، قمت باختباره في سيناريوهاتي الخاصة. مساعد حل المشكلات بلغة C++ الخاص بي على وشك الانتهاء من الاختبارات. يعتمد على بروتوكول MCP لإنشاء دفتر عمل تفاعلي. يمكنك طرح أسئلة بلغة C++ عليه، وسيقوم بإنشاء دفتر عمل تنفيذي خطوة بخطوة، مما يعزز بشكل كبير كفاءة التعلم، خاصة للأطفال.
يتعلق هذا السيناريو بالاستدعاء المتعدد للأدوات، حيث تعمل الذكاء الاصطناعي باستمرار وتنفذ الأدوات بينما تقوم بتحليل النتائج. كانت نتائج الاختبار مثالية تمامًا!
في كل جولة، يقيم النموذج بدقة حالة المهمة الحالية ويحدد الخطوات التالية. بلا شك، تم تدريب هذا النموذج خصيصًا للمهام المتعددة الجولات، وقد كنت أنتظر شيئًا من هذا القبيل منذ فترة طويلة.
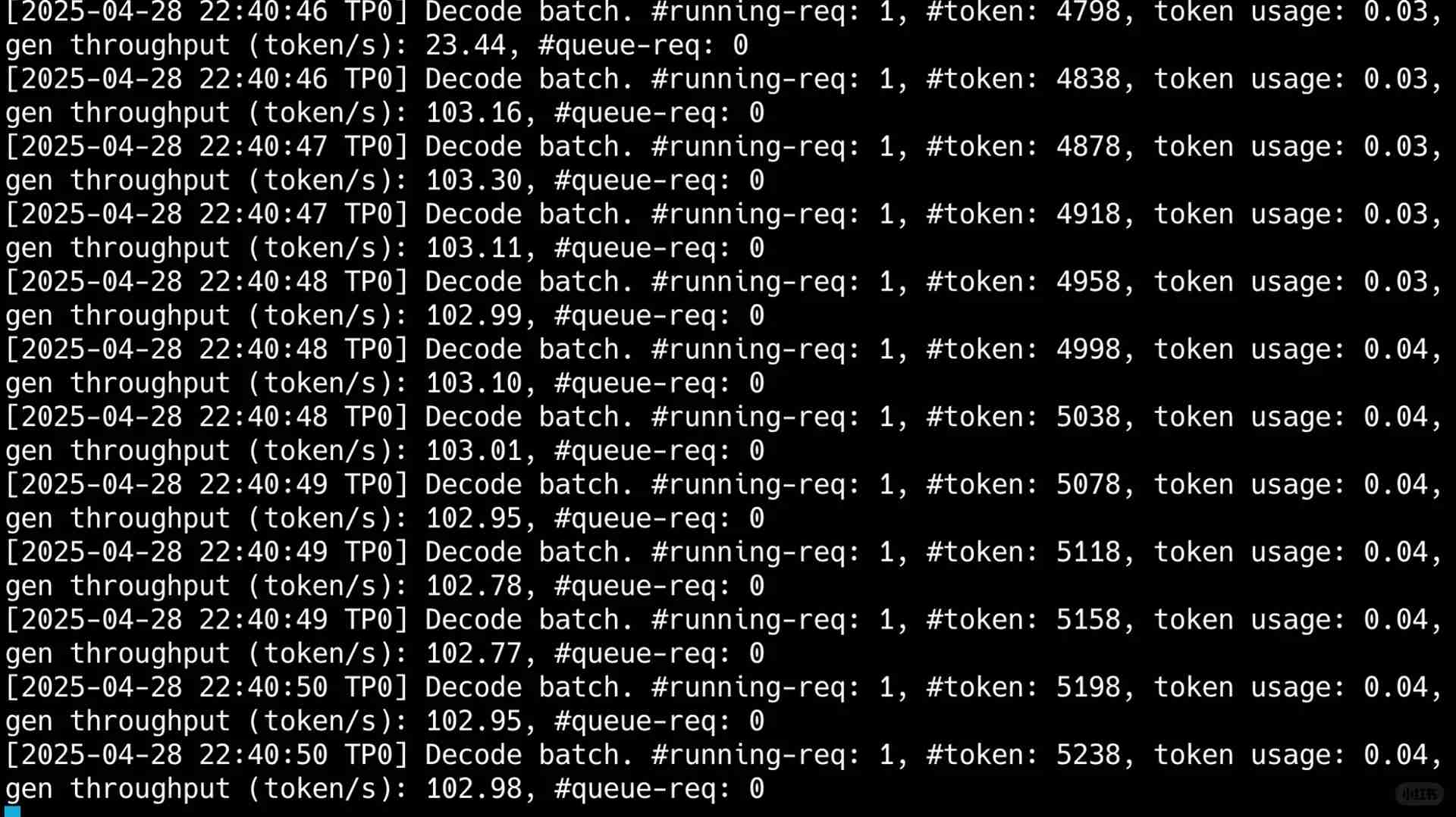
وما أذهلني حقًا كان معدل العبور للعميل الواحد، الذي تجاوز 100t في الثانية الواحدة. كما هو واضح في الصورة النهائية، على الرغم من استهلاك 50,000 رمز في سيناريو يتضمن استخدام أدوات متعددة الجولات، كان معدل الإخراج سريعًا للغاية، حيث تم إكمال العملية بأكملها في 40 ثانية فقط.
هل يبدو المستقبل بهذا الشكل: استخدام MOE نشط مدمج لمعالجة مشكلتي السرعة والتكلفة، تقديم أداء قوي بينما يتعامل مع أكثر المشاكل تعقيدًا في العملاء؟
الانتظار كان يستحق ذلك تمامًا. في الأيام القادمة، سأواصل إجراء اختبارات متعمقة على هذه النماذج بناءً على سيناريو العميل الخاص بتعلم C++. بالإضافة إلى ذلك، فيما يتعلق بالنموذج الذي يزيد عن 200B، أعتقد أنه قد يكون ممكنًا تشغيله على جهاز واحد مع بعض التعديلات باستخدام Ktransformer. هل يوجد أي شخص مهتم؟ إذا كان الأمر كذلك، سأكون سعيدًا بإجراء المزيد من الاختبارات.
إنه فعلاً إنجاز رائع أن تصل إلى هذا المستوى من الأداء مع Qwen3. لقد لاحظت بنفس الشيء، تحسين كفاءة الـ throughput يتطلب بعض التخصيص الجيد. هل جربت زيادة عدد الأجهزة لتحسين الأداء أكثر؟