GPT-4.1 versus Wenxin Yiyan: نتائج أداء مذهلة تُكشف في تقييم الذكاء الاصطناعي الأخير
🔥 حلبة كوريس للموديلات الكبيرة تطلق للتو! الإصدار الأول من تقييم GPT-4.1 — لا خدع، فقط الحقائق!

🌟 تقرير المعركة النهائية: 🏆 Gemini-2.5-Pro يظهر بأسلوبه الملكي، ولا شك في قوته المهيمنة على القائمة 💥 GPT-4.1 ≈ Qwen-2.5-Max، لكنه تفوق عليه OpenAI-O3-mini-high و o1 💰 GPT-4.1-mini ≈ النموذج الكلاسيكي DeepSeek-V3، يمكن اعتباره "الإصدار الشعبي لـ GPT-4.5" 😱 GPT-4.1-nano: تعرض لسحق كامل من قبل Wenxin Yiyan، والتجربة انهارت تمامًا...
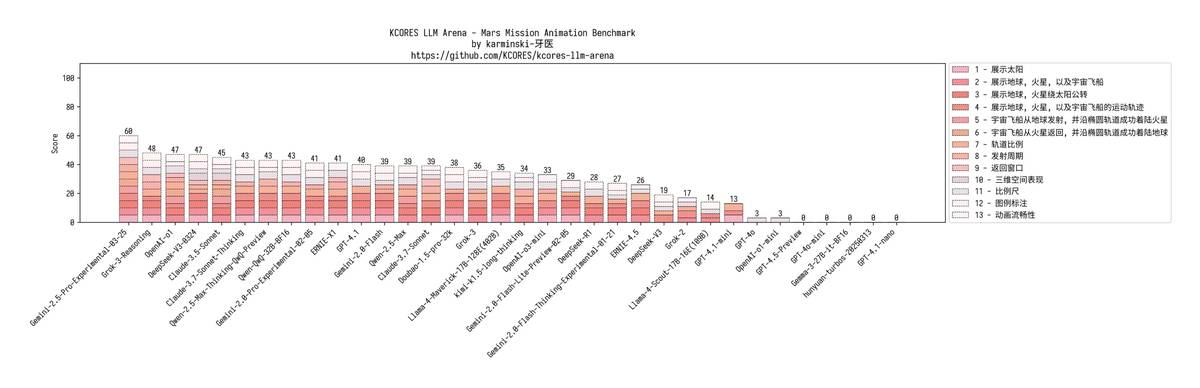
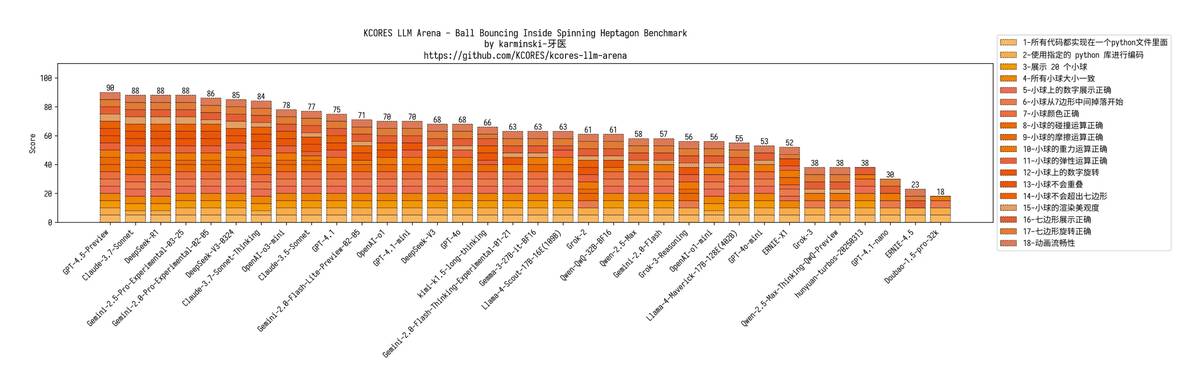
📊 سجل الاختبارات الصعبة (تحذير عالي الطاقة): 1. 🎮 تحدي محرك الفيزياء بـ 20 كرة جودة الشفرة الخاصة بـ GPT-4.1 عبر الإنترنت، لكنه لم يكن لديه تأثير الدوران بالاحتكاك الإصدار mini فشل أيضًا، والنسخة nano كانت أسوأ — بقيت كرة واحدة فقط ت蹦ت وحدها في الملعب
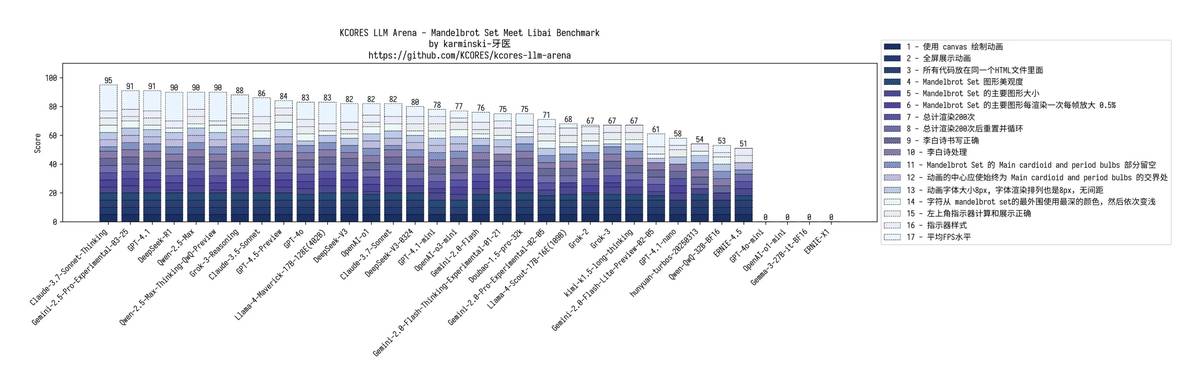
2. 🎨 إنشاء فن من مجموعة ماندلبورت GPT-4.1: الألوان مقلوبة تمامًا + انسداد في المشهد mini: خصم بسبب عدم الرسم الكامل للشاشة nano: فشل في التعرف على الأوامر، والنص تداخل بشكل عشوائي، وحدث خطأ في العناصر الأساسية، انهار تمامًا
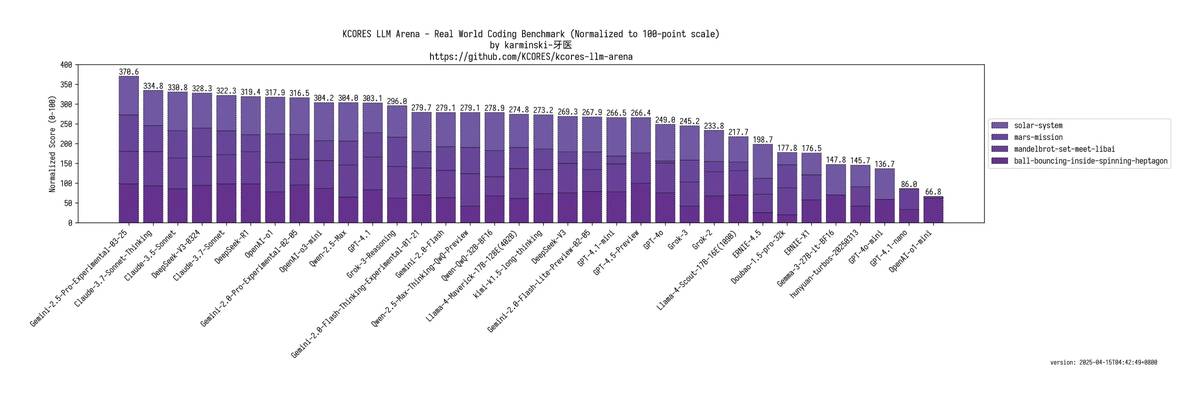
3. 🚀 اختبار الحد الأقصى للهبوط على المريخ المعركة أصبحت أكثر قسوة: GPT-4.1: مسار خاطئ، جميع النوافذ الزمنية للإطلاق خاطئة mini: حتى لم يتمكن من رسم مركبة الفضاء nano: حدث خطأ في الشفرة، وتوقف تمامًا
4. ☄️ اختبار كبير لنظام الكواكب GPT-4.1: هل هناك تداخل بين المريخ والشمس؟ عودة إلى نظرية الأرض المركزية؟ mini: أداء غير متوقع مستقر nano: رسم بعض الدوائر بشكل عشوائي كحل سريع
💡 مراجعة نهائية: GPT-4.1 هذه المرة كانت التوقعات مرتفعة جدًا والخيبة أكبر. على الرغم من الادعاء بالتحديث، إلا أنه كان "عادياً للغاية". هل تبحث عن الكمال؟ Gemini لا يزال الخيار الأول؛ إذا كنت محدودًا في الميزانية؟ mini يمكن أن تتعامل مع الأمر بصعوبة؛ أما nano... ننصح بعدم التفكير فيه!
🤖 وقت التفاعل: ما هو AI الذي أذهلك مؤخرًا؟ ومن الذي أصابك بالصدمة؟ 快来 قسم التعليقات، وابدأ "مؤتمر سخرية نماذج الذكاء الاصطناعي"!
المقارنة بين GPT-4.1 ووينشين ييان كانت مثيرة للاهتمام حقًا، خاصة النتائج المثيرة للدهشة في اختبارات الفيزياء والفنون. يبدو أن GPT-4.1 قوي جدًا ولكن الإصدارات الأصغر مثل nano كانت مخيّبة للآمال بشكل كبير.
واو، النتائج مذهلة حقًا! يبدو أن GPT-4.1 قوي جدًا ولكن لديه بعض الثغرات في النسخ الأصغر. بالمقارنة، وينشين ييان أثبت نفسه في اختبارات معينة، لكنه ليس دائمًا الخيار الأفضل. الإعدادات الصغيرة للنماذج تلعب دورًا كبيرًا في أدائها النهائي.
这篇文章的对比测试很有趣,尤其是看到GPT-4.1在一些复杂任务中的表现起伏。不过个人觉得,这些AI模型还是需要更多优化才能完全取代专业人士。文心一言的表现确实让人眼前一亮,期待未来能看到更强的迭代版本!