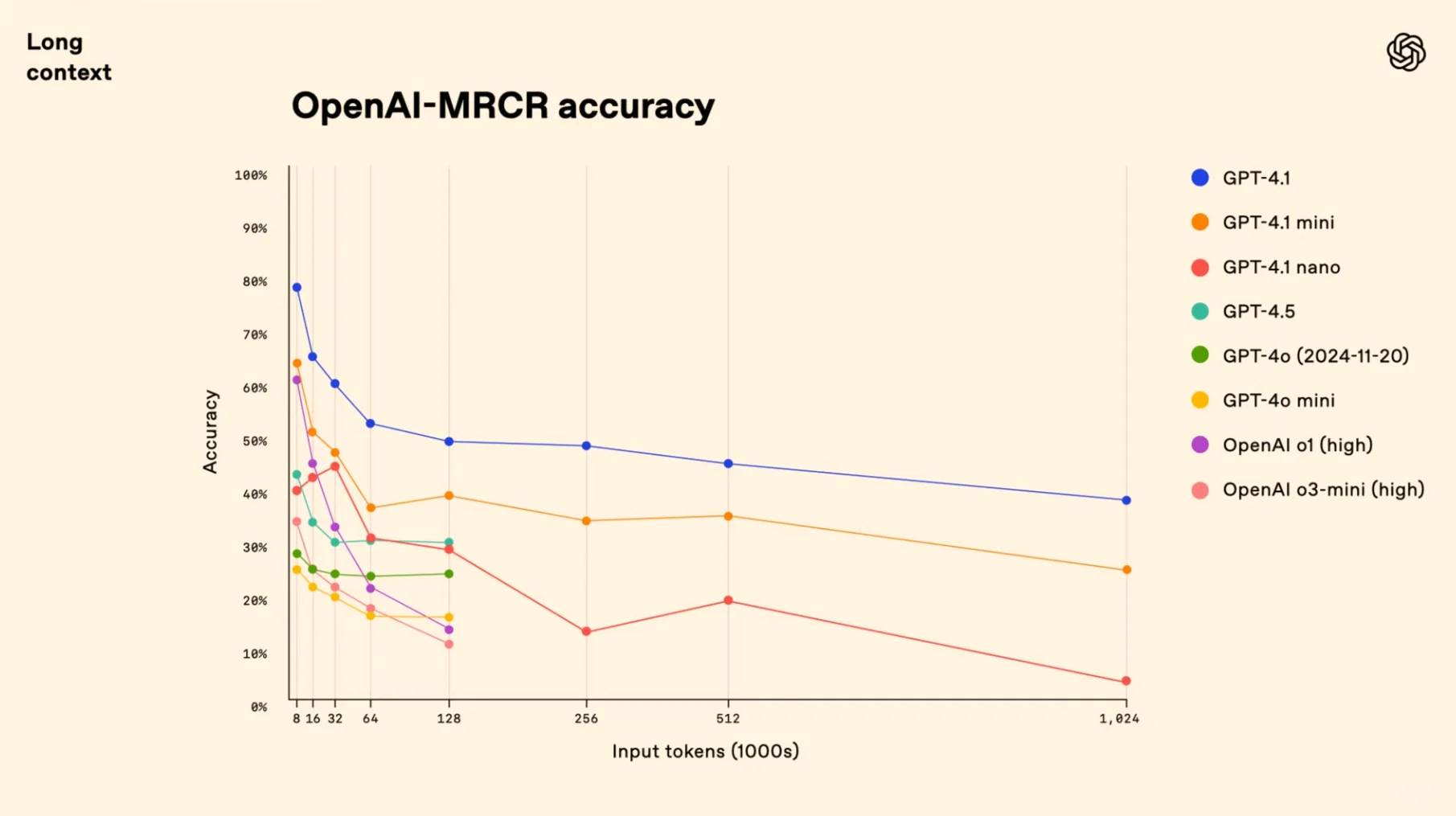
GPT-4.1 vs GPT-4o: OpenAI’s Latest AI Model Outperforms in Every Aspect
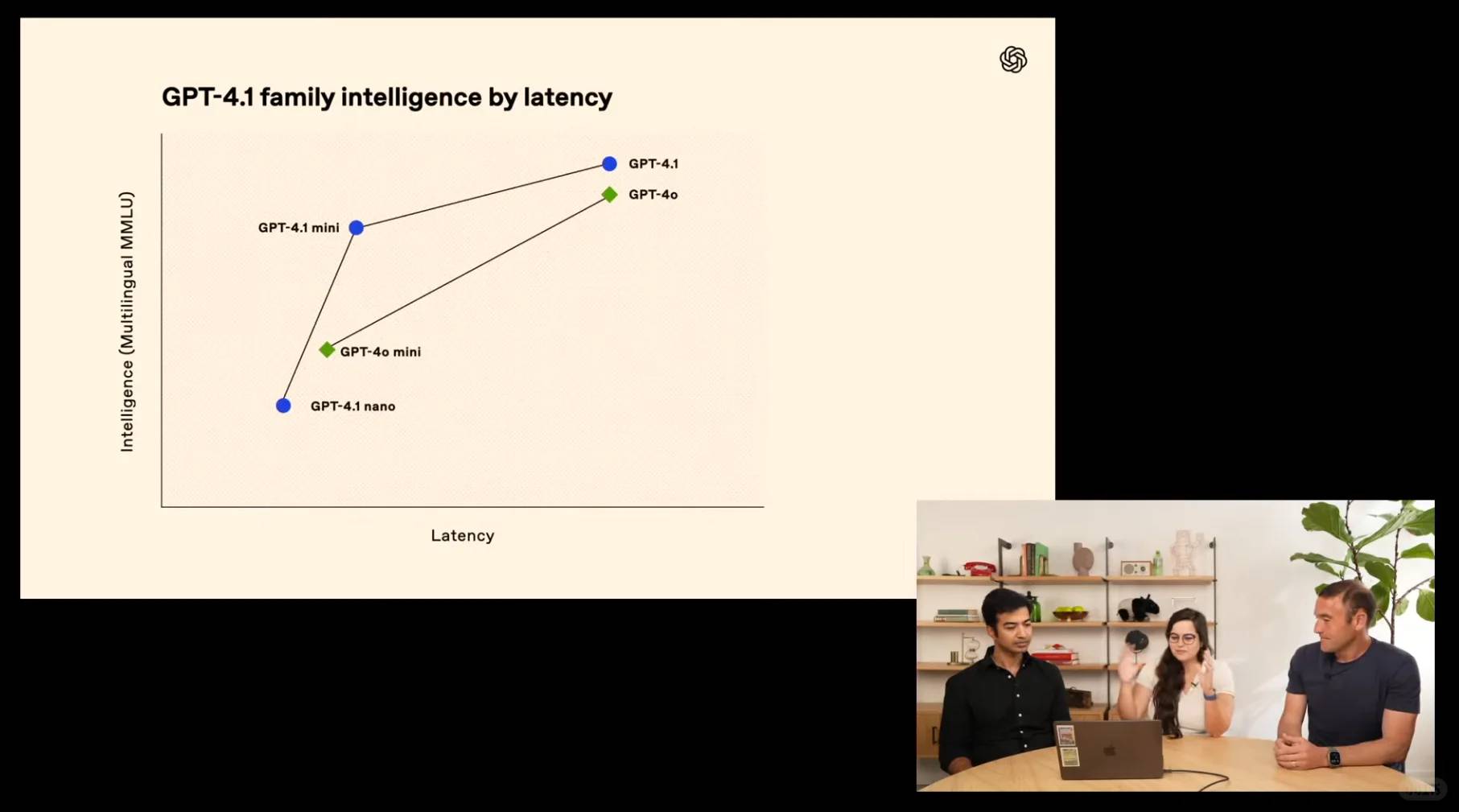
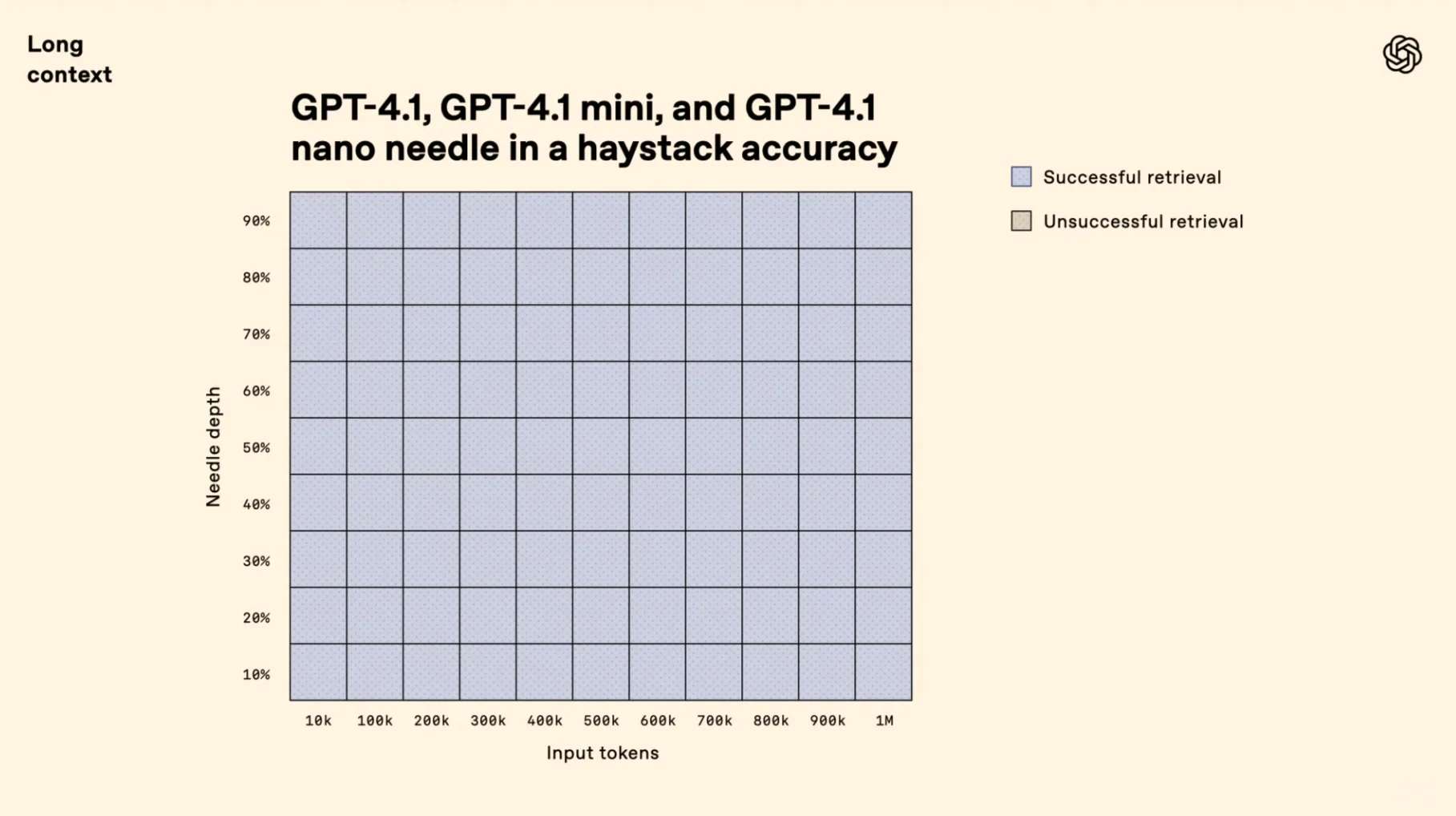
Introducing the game-changing trio: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano—outshining their predecessors with remarkable enhancements in coding prowess and instruction execution. These powerhouse models boast an expansive 1-million-token context window, delivering unprecedented long-context mastery. Witness how GPT-4.1 dominates industry benchmarks with its cutting-edge capabilities:
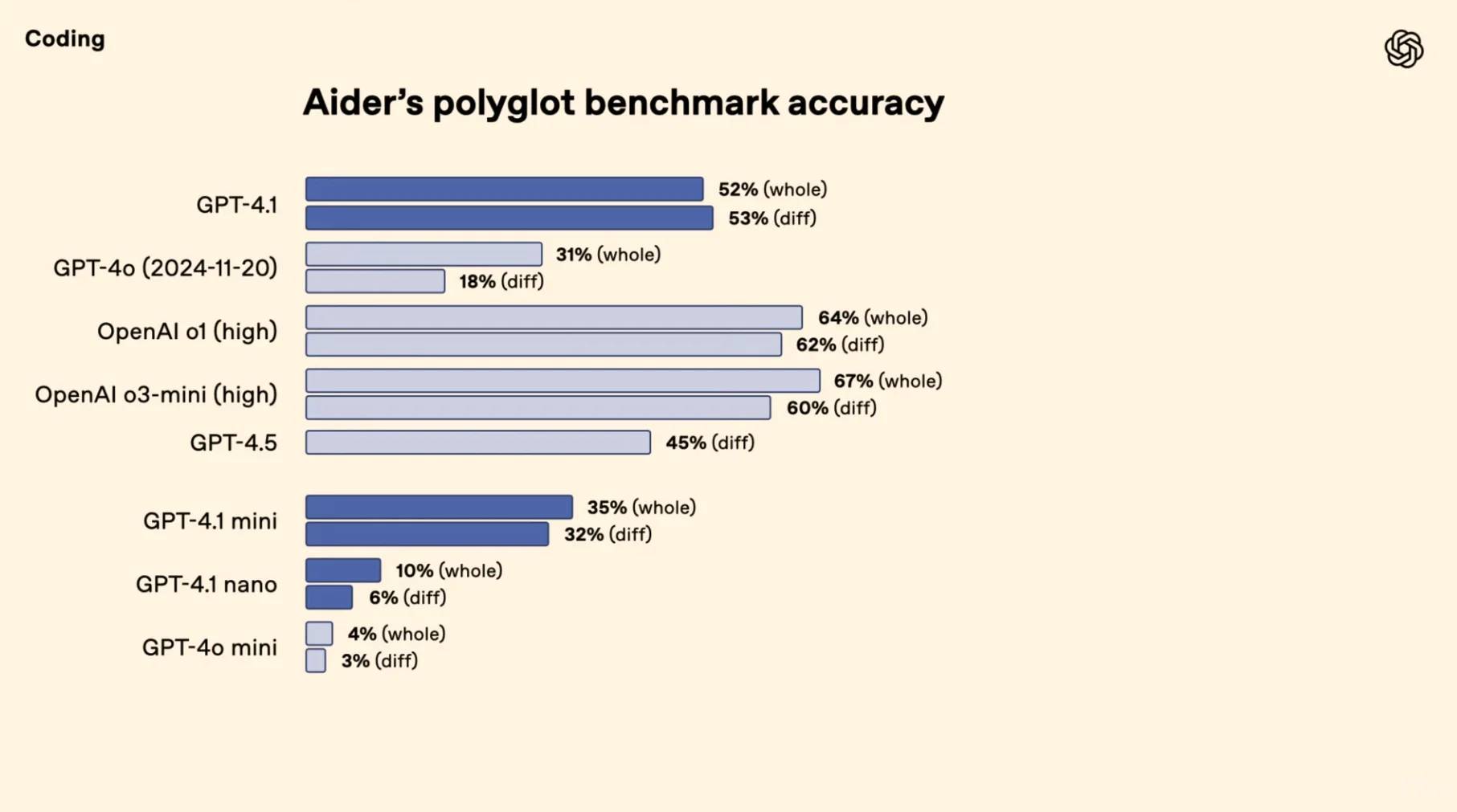
[🚀] **Coding Mastery**: Crushing the competition, GPT-4.1 achieves a staggering 54.6% pass rate on SWE-bench—soaring 21.4% above GPT-4o and 26.6% beyond GPT-4.5 to claim the coding crown.
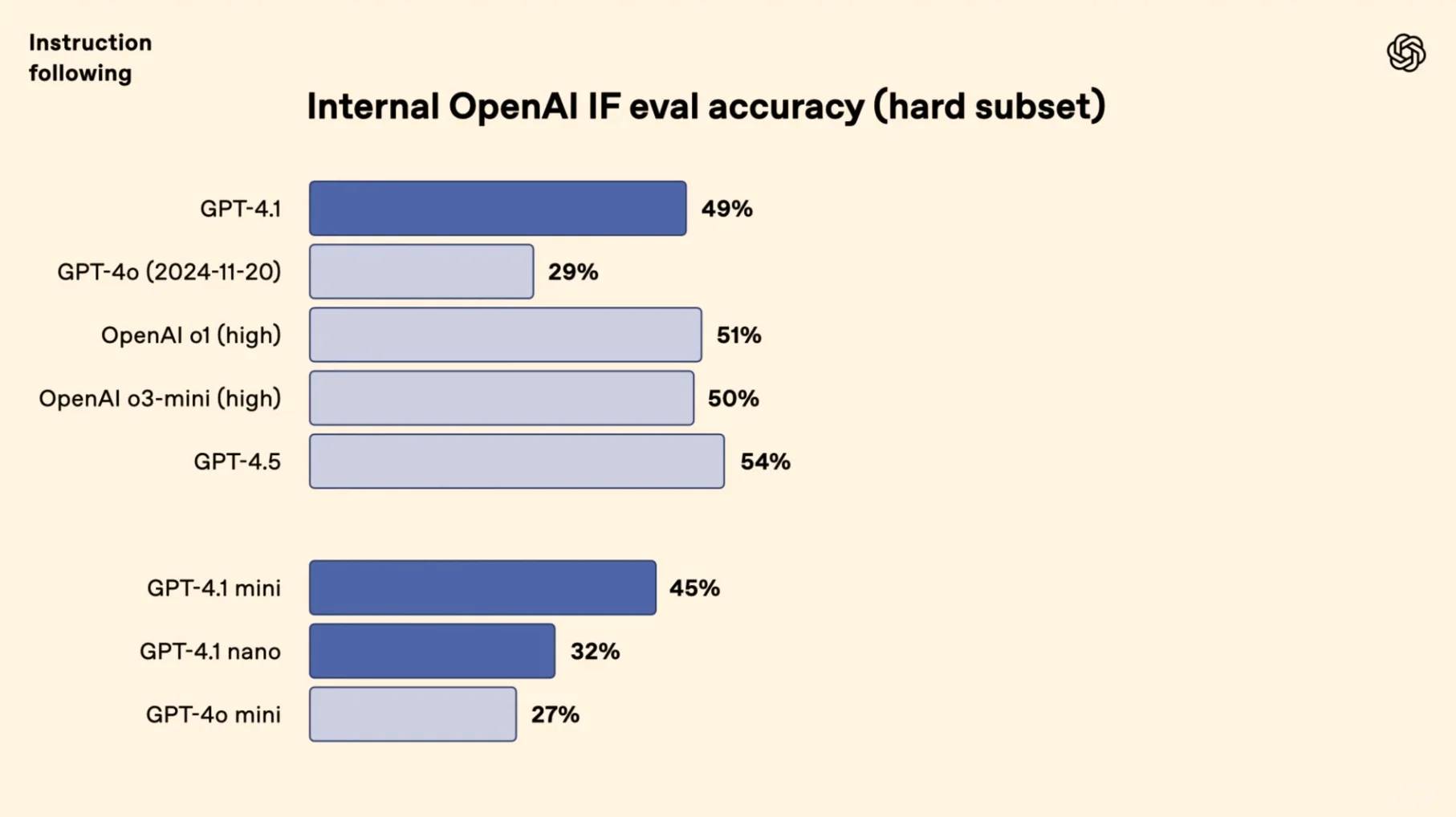
[🎯] **Precision Execution**: On Scale’s MultiChallenge, GPT-4.1 hits 38.3%, demonstrating a 10.5% leap in instruction-following finesse over GPT-4o.
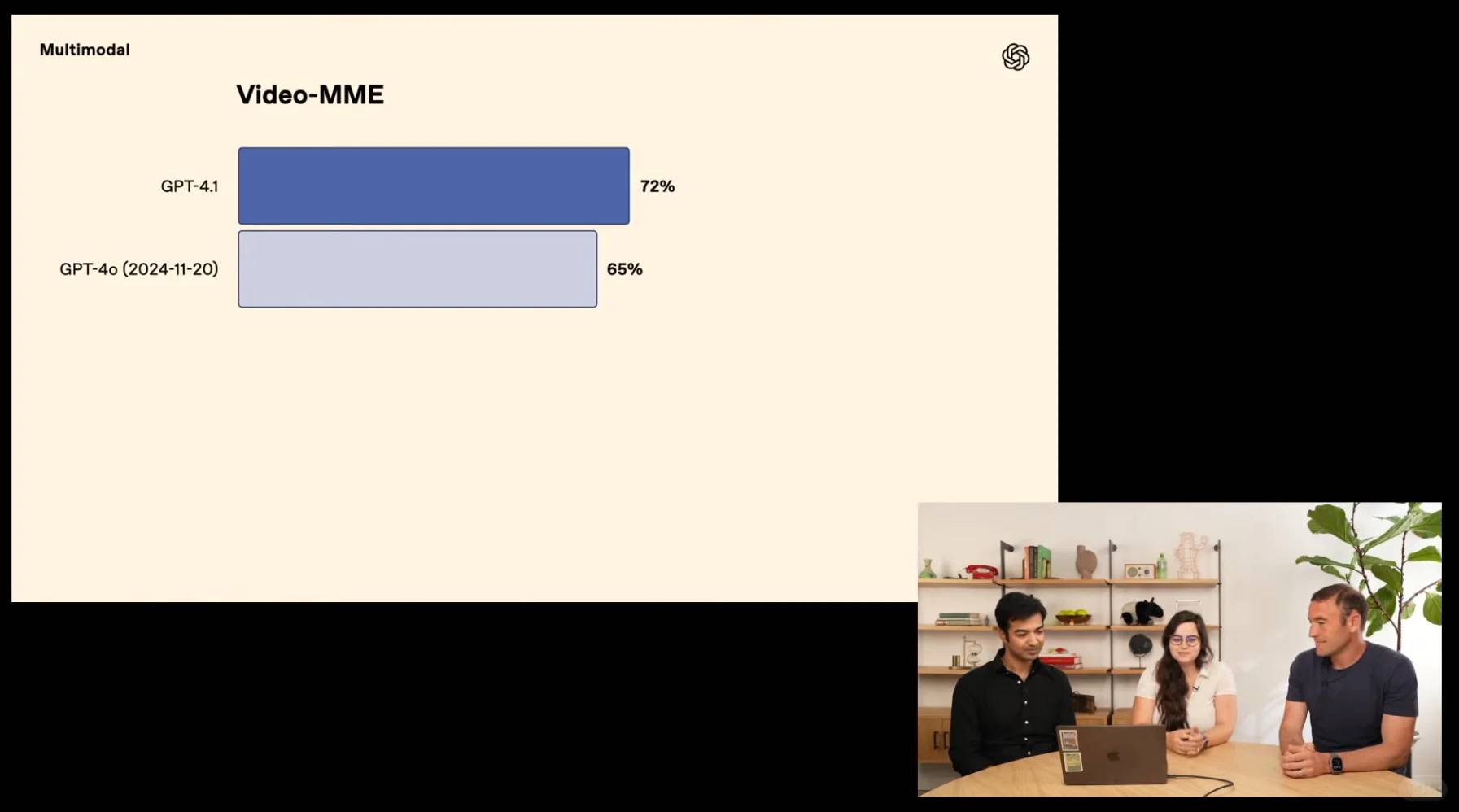
[🔍] **Context Champion**: Redefining boundaries, GPT-4.1 scores a record-breaking 72.0% on Video-MME’s multimodal assessment, eclipsing GPT-4o by an impressive 6.7% margin.

Wow, that 54.6% pass rate on SWE-bench is insane! I can’t believe how much better GPT-4.1 is at coding compared to the previous versions. The 1-million-token context window also sounds like it would be a game-changer for complex tasks. OpenAI is really pushing the boundaries with these updates.
Absolutely agree! The improvements in both coding capabilities and context handling are truly impressive. It’s exciting to see how these advancements can unlock new possibilities for developers and creatives alike. Thanks for your insightful comment—keep sharing your thoughts!
Wow, that 54.6% pass rate on SWE-bench is insane! I can’t believe how much better it is compared to previous versions. The long-context stuff sounds like a game-changer for complex projects. OpenAI really outdid themselves this time.
Absolutely agree! The improvements are truly remarkable, and that pass rate is impressive. It’s exciting to see how these advancements will empower developers tackling large-scale projects. Thanks for your insightful comment—keep sharing your thoughts!
Wow, that 54.6% pass rate on SWE-bench is insane! It’s crazy to see how much more GPT-4.1 can handle compared to its predecessors. I’m really curious to test it out for some complex coding projects. This could seriously change the game for developers.
Absolutely, the improvements in GPT-4.1 are remarkable! The higher pass rate on benchmarks like SWE-bench shows just how powerful this model has become for complex tasks. I think you’ll find it incredibly helpful for challenging coding projects. Exciting times ahead for developers! Thanks for sharing your thoughts!
Wow, that 54.6% pass rate on SWE-bench is insane! I can’t believe how much better it is compared to the previous versions. The ability to handle such a huge context window must give it an edge in complex tasks. OpenAI really outdid themselves this time.
Wow, those numbers on the SWE-bench are insane! I can’t believe how much of an improvement this is over previous versions. It’ll be fascinating to see what developers build with such powerful tools at their disposal now.
Absolutely, the improvements shown on the SWE-bench are impressive! It’s exciting to think about the possibilities as developers push the boundaries with these advanced tools. Your enthusiasm for the potential is exactly why we love seeing comments like this. Thanks for sharing your thoughts—let’s stay curious together!
Wow, that 54.6% pass rate on SWE-bench is insane! It’s crazy to see how much of an improvement this is over previous models. I’m really curious to test out the Nano version myself; sounds like it could be a game-changer for smaller projects.
Absolutely, the improvements are impressive! The Nano version is indeed exciting, offering great performance for lightweight tasks without compromising too much on capability. If you get a chance to try it, let me know what you think—your feedback would be valuable. Thanks for your interest and engagement!
Wow, that 54.6% pass rate on SWE-bench is insane! I can’t believe how much of an improvement this is over the previous versions. The long-context capabilities must be a game-changer for complex projects. I’m really curious to see what other industries will adopt these models next.
Wow, that 54.6% pass rate on SWE-bench is insane! It’s crazy to see how much more GPT-4.1 can handle compared to previous versions. I wonder how long it’ll take for these advancements to trickle down to smaller apps and tools. The future of coding with AI just keeps getting better!
Absolutely, the progress we’re seeing is incredible! It could still be a while before these advanced capabilities are widely available in smaller tools, but the momentum is definitely building. Exciting times ahead for sure! Thanks for your insightful comment!
Wow, those numbers for GPT-4.1’s coding performance are insane! I’m especially impressed by that massive leap over GPT-4o—it really shows how much extra training and tweaks can make a difference. I wonder how long it’ll take other models to catch up. Exciting stuff for developers and tech enthusiasts alike!
Absolutely, the advancements in GPT-4.1 are remarkable! The improvements in coding performance highlight the power of incremental updates and additional training data. It’ll likely be some time before others catch up, but competition always drives innovation. Thanks for your insightful comment—excited to see where this technology goes next!
Wow, that 54.6% pass rate on SWE-bench is insane! I can’t believe how much more efficient GPT-4.1 is compared to its predecessors—it feels like we’re really entering a new era of what AI can do. The expanded context window alone seems like it would make such a big difference for complex projects. I’m curious to see what other industries will adopt these models next.
Wow, those numbers on the SWE-bench are insane! It’s amazing to see such a big leap in coding ability compared to the previous versions. I wonder how long it will take for other models to catch up. This is definitely a game-changer for developers.
Wow, those numbers on the SWE-bench really highlight the difference! It’s crazy to see how much more GPT-4.1 can handle compared to previous versions. I wonder how long it’ll take for other companies to catch up. This feels like a whole new level of capability.
Wow, those numbers for GPT-4.1’s coding performance are insane! I can’t believe how much it outpaces the previous models—it feels like we’re getting closer to true AI-driven development tools. I wonder what this means for software engineers and developers—will this make coding more accessible or just automate even more jobs? Exciting times ahead either way!
Wow, that 54.6% pass rate on SWE-bench is insane! It’s amazing how much progress they’ve made with the new context window—it feels like we’re really stepping into the future of AI. I wonder what kind of real-world applications this level of coding ability could unlock.
Wow, those coding improvements are insane! I’m especially impressed by that 54.6% pass rate—it really shows how much more efficient it could be for developers. I wonder how long it’ll take for these advancements to trickle down to everyday tools we use. Exciting stuff!
Wow, that 54.6% pass rate on SWE-bench is insane! It’s crazy to see how much more GPT-4.1 can handle compared to previous versions. I wonder how long it’ll take for these advancements to trickle down to smaller apps and services. This feels like a whole new level of capability.
Wow, that 1-million-token context window is insane! I’ve been struggling with GPT-4o losing track in long conversations, so this upgrade sounds like exactly what I need. The coding performance jump is impressive too – might finally convince my team to upgrade our dev tools.
Wow, that 1-million-token context window is insane! Makes me wonder how this will change how we interact with AI for complex tasks like coding or research. The performance jump from GPT-4o seems massive – especially that 54.6% SWE-bench score. Can’t wait to test it out myself!
Thanks for your enthusiasm! The 1M-token window is indeed a game-changer—it allows for deeper context retention in coding sessions or research analysis without losing track. I’m particularly excited about the SWE-bench improvements too; it feels like we’re getting closer to AI that can handle real-world dev tasks seamlessly. Can’t wait to hear about your experience once you try it!
Wow, the performance jump from GPT-4o to GPT-4.1 is insane, especially in coding tasks! That 1-million-token context window sounds like a game-changer for handling complex projects. Can’t wait to see how developers leverage these improvements in real-world applications.
Absolutely! The expanded context window and coding enhancements in GPT-4.1 are truly transformative—I’m especially excited to see how it streamlines large-scale codebases and debugging. Developers will likely unlock some incredible workflows with these upgrades. Thanks for sharing your enthusiasm!
Wow, that 1-million-token context window is insane! The coding performance jump from GPT-4o to GPT-4.1 seems massive – wonder how this will affect developers’ workflows. Still curious about real-world use cases where these benchmarks actually translate to noticeable improvements though.
Thanks for your thoughtful comment! The expanded context window is indeed game-changing—it allows developers to process entire codebases at once, making debugging and refactoring significantly smoother. From what I’ve seen, real-world improvements include faster prototyping and more accurate autocomplete in IDEs. Personally, I think the biggest impact will be on complex, long-term projects where maintaining context is crucial.
The performance jump from GPT-4o to GPT-4.1 is insane, especially that 54.6% SWE-bench score! I wonder how much better it handles complex coding tasks compared to previous versions. The 1-million-token context window sounds like a game-changer for long documents too.
Wow, that 1-million-token context window is insane! I’ve been using GPT-4o for coding help, but if GPT-4.1 really delivers that 54.6% SWE-bench pass rate, I might need to switch immediately. The performance jump seems way bigger than I expected between versions.